Data pipeline Project(feat. AWS)
데이터 엔지니어링 사이드 프로젝트



Data pipeline 구축 목표
사실 이전에 대학교 때 쇼핑몰 데이터를 MySQL서버에 저장해서 분석해보는 프로젝트를 진행한 경험이 있습니다.
여기에 조금 더 조미료를 추가해서 AWS를 이용해서 클라우드에선 어떻게 사용하는지 배우기 위해 이 프로젝트를 기획했습니다.
Process
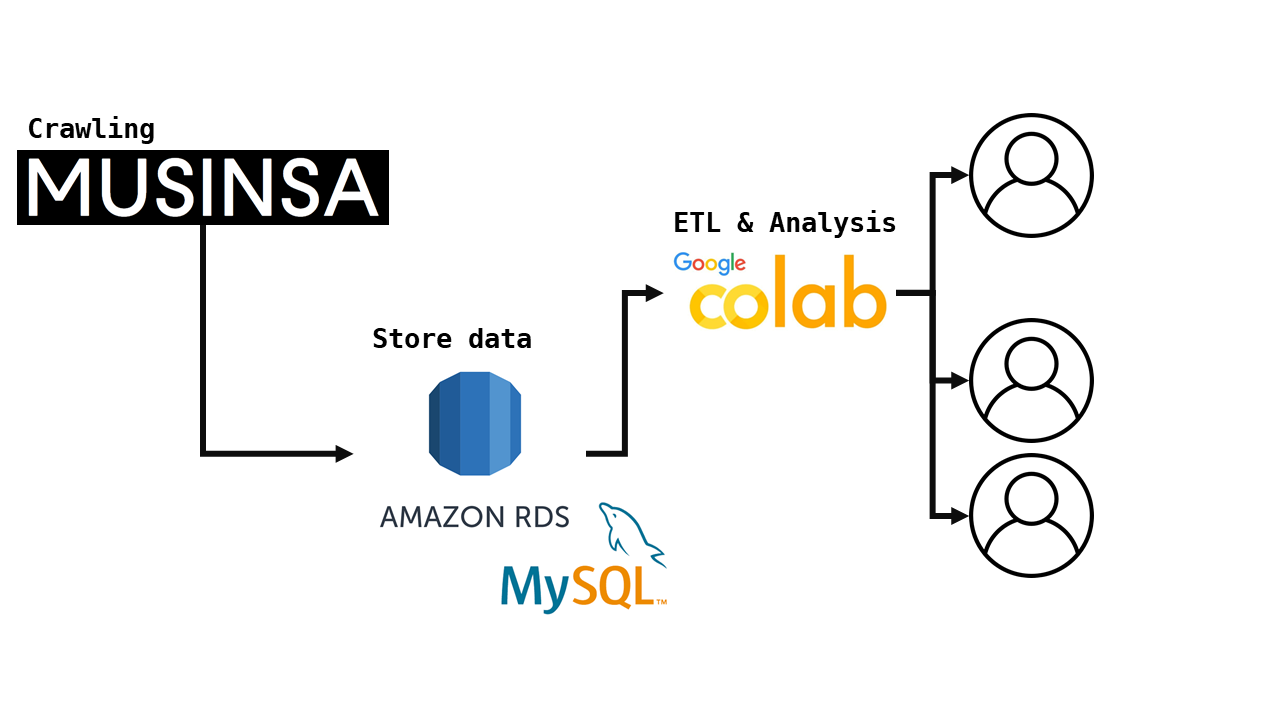
- 무신사 홈페이지에서 카테고리별 제품 크롤링
- AWS RDS에 접속하여 데이터 적재
- Colab에서 접속해서 ETL
Source
- 무신사 제품
- AWS RDS(MySQL)
- Colab
WHY
- 기존에 있던 프로젝트 구성 당시에도 그리고 현재에도 자주 사용하고 애정있는 쇼핑몰인 무신사를 선택했습니다.
- 최근 채용공고에 빠질수 없는 클라우드 서비스로 GCP, AWS, AZURE가 있습니다. 이 3개 중 시장 점유율이 가장 높은 AWS를 이용했습니다.
- MySQL은 데이터를 다루는데 매우 기초가 되는 언어라 생각되어 MySQL로 구성했습니다. 또한 제가 사용해본 경험이 있기 때문입니다.
- 차후 파이썬, 아나콘다, 또는 개발환경이 세팅되어있지 않은 사용자가 있을 수 있고 접근 용이성이 높은 Colab을 이용할 수 있도록 했습니다. 기존 개발환경이 있으신 분들은 해당 환경을 그대로 사용해도 됩니다. ## Library
- urllib.request urlopen
- bs4 BeautifulSoup
- requests
- re
- pymysql
- pandas
- numpy
- logging
Tip: 해당 코드는 Github MUSINSA_DATA_PIPELINE_AWS에서 확인할 수 있습니다.
Part 1: 데이터 수집하기
해당 코드는 github의 code파일 products.ipnby에 있습니다.
Part 2: AWS RDS & SQL
RDS 생성하기
RDS에 접속하여 DB생성하기를 합니다.
저는 돈이 없는 취준생이기 때문에 Free tier로 간단하게 만들었습니다.
인바운드 규칙 추가하기
RDS에 접속할 수 있는 IP를 지정하는 작업입니다. 이를 통해서 특정 IP에서 RDS에 저장된 데이터를 접근할 수 있습니다.
1. RDS - 데이터베이스 - 보안그룹
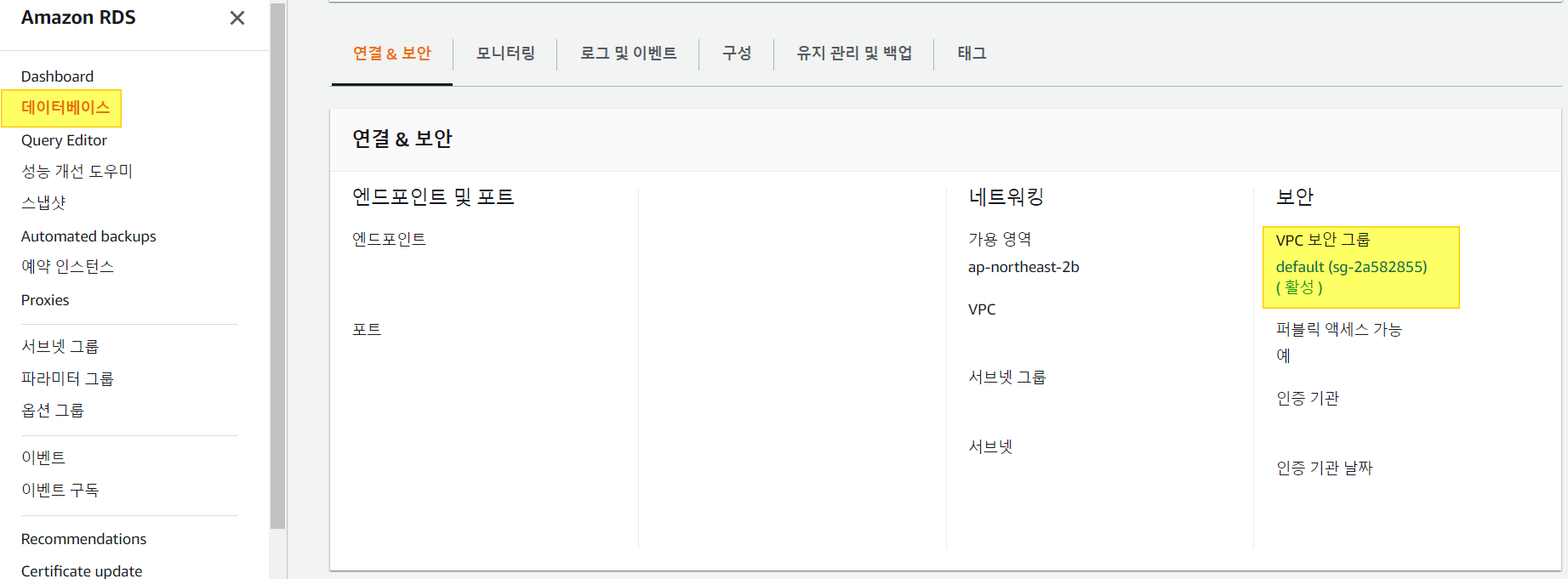
2. Edit Inbound rules
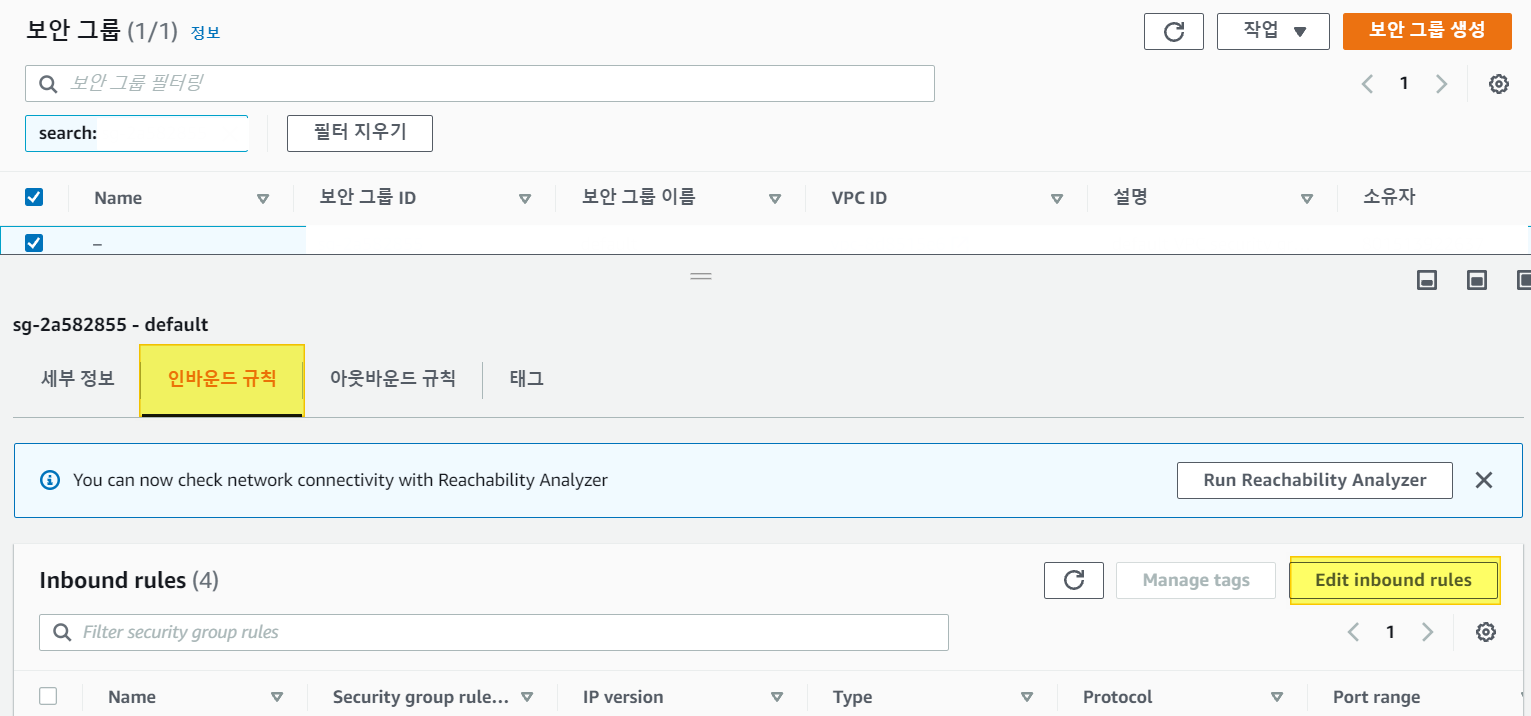
3. 규칙 추가 - MySQL - IP 설정 - 규칙추가
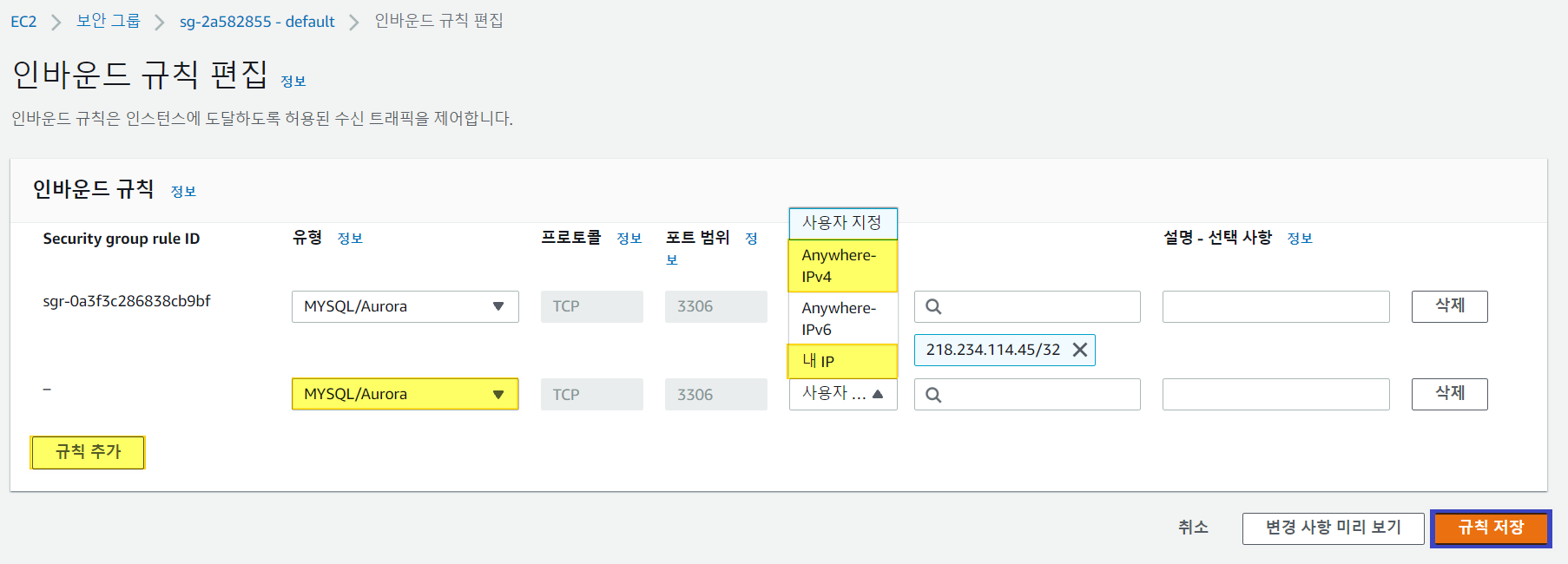
- 모든 IP에서 접속 허용 IPv4
- 현재 IP에서만 접속 허용 내 IP
이제 특정 IP에서 저희가 만든 AWS RDS에 접속할 수 있습니다.
저는 SQL Workbench에서 새로운 Connection을 연결해줍니다.
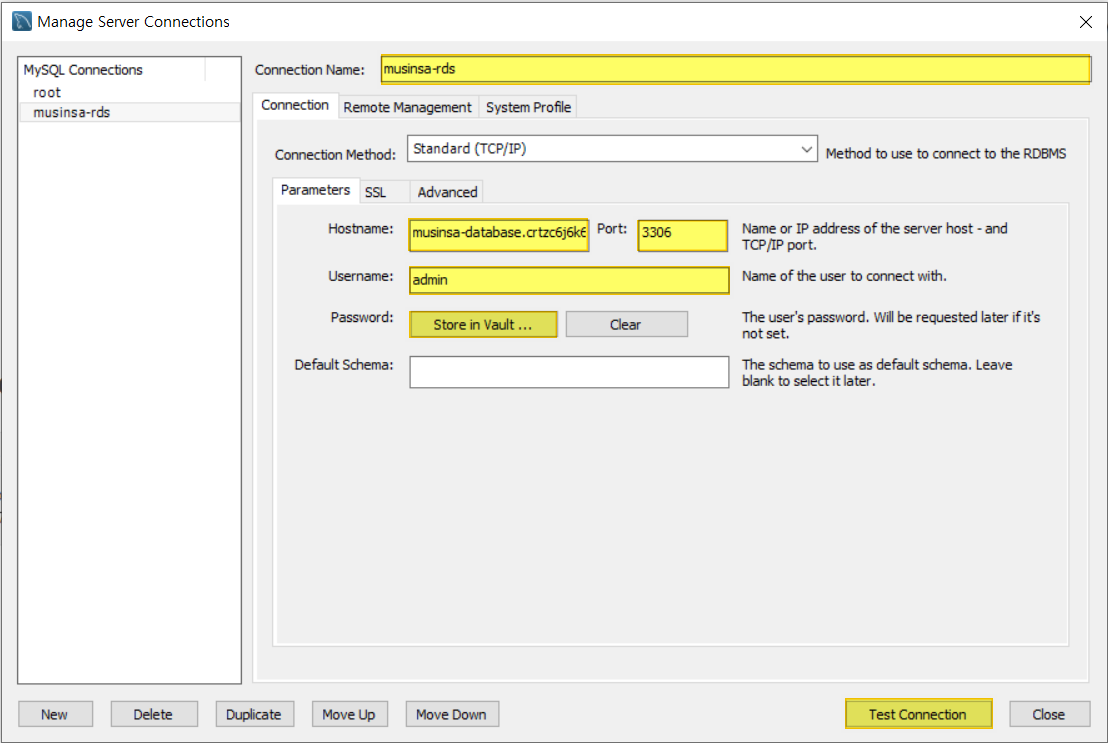
- connection name: 연결 이름 아무렇게 지어도 괜찮습니다.
- Hostname: RDS DB인스턴스의 엔드포인트
- Port: RDS DB인스턴스의 Port
- Username: DB생성시 작성한 username
- Password: DB생성시 작성한 Password 꼭 기입해주세요
다 기입한 후에 Test Connection으로 검증해보세요
해당 코드는 github의 query파일에 있습니다
# username= DB생성시의 이름
# password= DB생성시 기입한 비밀번호
# database= mysql에서 생선한 DB 이름
db = pymysql.connect(host=host, user=username, password=password, db=database, port=3306)
cursor=db.cursor()
cursor.execute("select * from products")
result=cursor.fetchall()
db.close
df=pd.DataFrame(result)
df.head()
df.columns=['name','brand','price','category','date']
df.head()
위와 같이 pymysql을 이용해서 데이터를 불러왔습니다. 이후에는 데이터를 이용해 ETL 및 EDA를 진행할 수 있을 것입니다.
마치며
약 2주 간 매일같이 한 프로젝트는 아니지만 그 사이에 배운점이 많았습니다.
- data type에 맞는 저장소를 선택해야 합니다.
현재 수집하는 데이터가 정형데이터인지 그럼 어떤 툴을 사용할 것인지 용량을 얼마나 산정해뒀는지 미리 고려해볼 것이 많다는 것을 알게되었습니다. - AWS 사용법
프리티어로 만들었지만 다른 형태의 저장소도 많이 지원하는 것을 확인했습니다. 데이터를 얼마나 자주 변경하는지에 따라 S3 budgket를 사용할 수도 있고 자주 변경하지 않는다면 RDS를 사용하는것이 바람직합니다. 또한 보안설정을 통해 해당 서비스에 액세스할 수 있도록 하는 방법을 배웠습니다. - 코드 리뷰
작년에 작성한 코드를 현재 돌려보니 작동이 원활하지 않았습니다. 크롤링 할려는 페이지가 변경된 것도 있었습니다. 코드들을 살펴보고 조금 더 간결하고 읽기 쉽게 만들려고 노력했습니다. 특히 작년 코드에선 세일 가격을 불러오지 못했었습니다. 단지 제품의 원가만을 담았다면 이번에는 세일이 진행중이라면 세일 가격을 담을 수 있도록 했습니다.
사실 아직 문제점도 있습니다. 아직 고객에 대한 데이터가 없으며 보안에 취약합니다. SQL서버에서 사용자의 Rule을 지정하여 원본 데이터를 훼손시키지 않도록 해야합니다.
기존에 있던 프로젝트를 리팩토링하며 얻은 것이 많아서 기분이 좋습니다. 제 글을 통해서 기초적인 데이터 파이프라인 구축에 어려움이 조금이나마 덜어졌다면 좋겠습니다.