cs231n 7강 Review
Lecture 7 Training Neural Networks II



Model Ensembles
- 독립적으로 N개의 모델을 훈련
- 결과는 N개의 모델 결과의 평균을 사용
모델의 개수가 늘어날수록 overfitting을 줄어들고 성능은 조금씩 향상 --> 일반적으로 2% 향상
- Same model, different initializations
교차 검증을 사용하여 가장 좋은 하이퍼 파라미터를 결정한 다음 가장 좋은 하이퍼 파라미터 세트로 여러 모델을 훈련 시키되 다른 임의 초기화를 사용하십시오. 이 접근법의 위험은 다양성이 초기화 때문이라는 것입니다
- Top models discovered during cross-validation
교차 검증을 사용하여 최상의 하이퍼 파라미터를 결정한 다음 상위 몇 개 (예 : 10 개)의 모델을 선택하여 앙상블을 구성합니다. 이것은 앙상블의 다양성을 향상 시키지만 차선의 모델을 포함 할 위험이 있습니다. 실제로 교차 검증 후 모델을 추가로 재 학습 할 필요가 없으므로 수행하기가 더 쉬울 수 있습니다.
- Different checkpoints of a single model
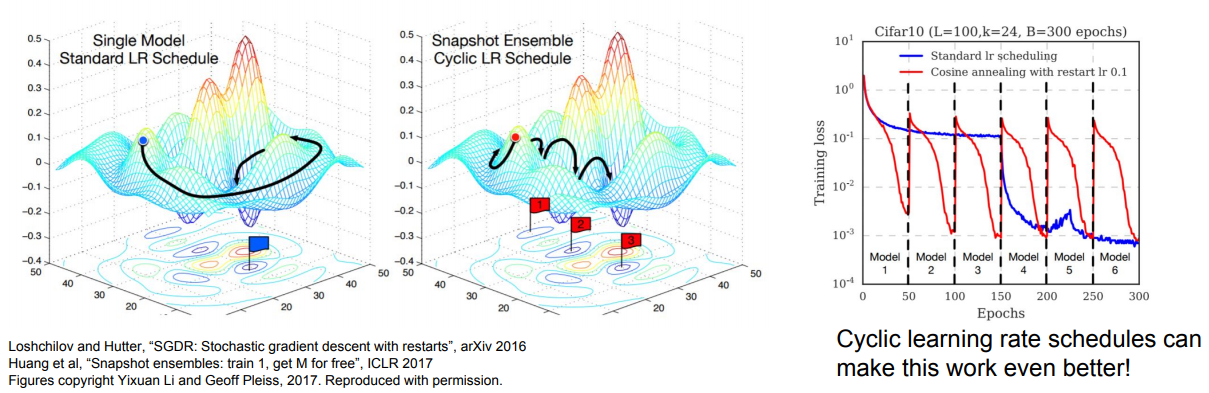
training cost가 매우 비싸다면(소요시간, 장비 등), 단일 네트워크 학습 도중 중간 모델들을 저장하고 앙상블로 사용할 수 있습니다. 여러 체크 포인트에서 나온 예측값들을 평균을 내서 사용합니다. 분명히 이 접근법은 다양성이 부족하지만 실제로 합리적으로 잘 작동합니다. 이 방법의 장점은 매우 저렴하다는 것입니다.
가장 우측에서 그래프는 Learning rate를 엄청 올렸다 내렸다를 반복합니다. 이 방식을 통해 손실 함수에 다양한 지역에서 수렴할 수 있도록 해줍니다
- Running average of parameters during training
마지막 요점과 관련하여 거의 항상 성능의 추가 비율을 얻는 저렴한 방법은 훈련 중에 이전 가중치의 기하 급수적으로 감소하는 합계를 유지하는 네트워크 가중치의 두 번째 사본을 메모리에 유지하는 것입니다. 이렇게하면 지난 몇 번의 반복에서 네트워크 상태의 평균을 구할 수 있습니다. 마지막 몇 단계에 걸친 가중치의이 "부드러운"버전이 거의 항상 더 나은 유효성 검사 오류를 달성한다는 것을 알 수 있습니다. 염두에 두어야 할 대략적인 직관은 목표가 그릇 모양이고 네트워크가 모드를 뛰어 넘고 있으므로 평균이 모드에 더 가까울 가능성이 더 높다는 것입니다.
How to imporve single-model performance?
Regularization
정규화는 우리가 모델에 어떤 data를 추가할 때 모델이 training data에 fit되게 하는 것을 막아줍니다.
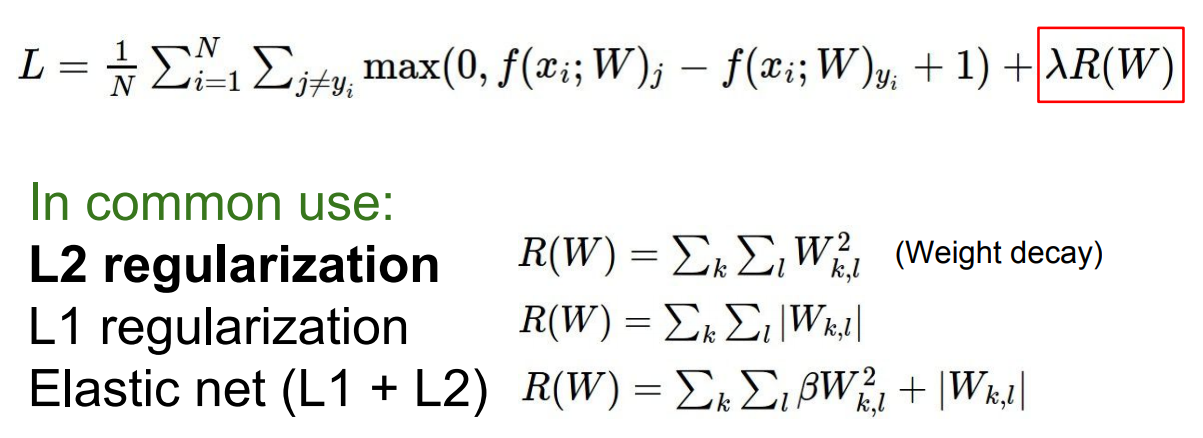
앞선 강의에서 이미 몇가지 regularization 기법들을 봤습니다. 보통 Loss에 항을 삽입하는 방식이였습니다.
사실 L2 regularization은 Neural network에서 그다지 좋은 성능을 보이지 않습니다. 가장 많이 사용하는 regularization은 바로 Drop out입니다.
Drop out
CNN을 배울 때 이미 배우셨을 수도 있습니다.
방식은 매우 간단합니다. forward pass과정에서 임의로 일부 뉴런을 0으로 만드는 것입니다.
- 일단 한 레이어의 출력을 전부 구하기
- 랜덤하게 일부를 0으로 만들기
- 그 결과값을 다음 레이어로 넘기기
Conv net에서는 전체 feature map에서 dropout를 시행하여 여러 channel중에 일부를 dropout시킬 수도 있습니다
import numpy as np
p=0.5 #얼마만큼 남길지, 값이 높을수록 0으로 만드는 비율이 줄어듭니다.
def train_step(X):
H1 = np.maximum(0, np.dot(W1, X)+b1)
U1 = np.random.rand(*H1.shape) < p
H1 *= U1 #drop
H2 = np.maximum(0, np.dot(W2, H1)+b2)
U2 = np.random.rand(*H2.shape) < p
H2 *= U2 #drop
output= np.dot(W3, H2)+b3
일부 값들을 0으로 만들면서 네트워크를 심하게 훼손한다고 생각할 수 있습니다. 근데 왜 이 방법이 좋은 것일까요?
특징들 간의 상호작용(co-adaptation)을 방지합니다.
예를들어 고양이를 분류하는 네트워크에서 어떤 feature는 눈,코,입,귀,꼬리 등을 담당할텐데 이것들을 취합해서 고양이인지 아닌지를 분류합니다.Drop out은 이 때 일부 feature에만 의존하지 못하게 해줍니다.
또한, Dropout의 새로운 해석은 단일 모델로 앙상블 효과를 가질 수 있다는 것입니다. 일부 뉴런들이 죽으면서 원본 모델의 서브셋 모델들이 여러가지 생기는 것처럼 보이지 않나요?
따라서 Dropout은 서로 파라미터를 공유하는 서브네트워크 앙상블을 동시에 학습시키는 것이라 생각할 수 있습니다. 사실 뉴런 개수의 따라 학습할 모델수가 기하급수적으로 증가하기 때문에 모든 서브네트워크를 사용하는건 사실상 불가능합니다.

test시에 랜덤하게 들어가는 drop out은 좋지 않습니다. 오늘은 잘 분류하다가 내일은 또 잘못 분류하면 여간 골치아픈게 아닐테니까요.
대신 그 임의성(randomness)을 average out시킵니다. 사실 밑에 적분식을 다루기 좀 까다롭습니다.
다행히 dropout의 경우에는 일종의 locally cheap한 방법을 이용해 위 적분식을 근사화시킬 수 있습니다.

dropout(p=0.5)를 적용해서 학습한다고 가정해 봅시다
train time에서의 기댓값을 위와 같이 구할 수 있습니다. dropout mask에는 4가지 경우의 수([0,0],[0,1],[1,0],[1,1])가 존재합니다. 그 후 4개의 마스크에 대해 평균화 시켜줍니다. 이 부분에서 test/train 간의 기댓값이 서로 상이합니다.
여기서 stochasticity를 사용하지 않는 가장 쉬운 방법은 test에 p를 출력 네트워크에 곱하여 똑같이 만들어 줍니다.