[cs231n] 12강 리뷰
Visualization and Understanding
12강 Visualizing and Understanding

- Activation values를 기반으로 해당 특징이 무엇을 찾고 있는지
- Gradient를 이용해 새로운 이미지를 만드는 방법
- 위와 같은 방법들로 CNN을 좀 더 깊숙이 이해하고 활용할 수 있도록 해보는 것이 목표입니다.
How to Understand inside of CNN

가장 쉽게 찾아볼 수 있는 것은 첫 번째 Layer입니다.
AlexNet같은 경우는 3x11x11 형태의 필터를 64개 갖고 있습니다. 이 필터들은 sliding window로 이미지를 쓱쓱 돌 것입니다. 그렇게 돌고 나서 가중치와 내적한 결과가 첫 번째 Conv Layer의 출력입니다.
하지만 첫 번째 Layer는 이미지와 직접적으로 연산을 수행하기 때문에 해당 필터가 이미지에서 어떤 것을 찾고 있는지 알기 쉽지 않습니다. 그래서 11x11x3 rgb를 시각화하여 본 것이 위 그림입니다. 가장 많이 찾을 수 있는 것은 엣지 성분입니다. (흰/검, 보색)
신기한 점은 CNN을 어떤 모델/데이터로 학습하건 첫 번째 레이어는 전부 다 비슷하게 생겼습니다. 첫 강의에서 나온 인간의 시각체계 또한 oriented edge를 찾는 것을 생각해본다면 매우 신기합니다.
</div>
Q: 필터의 가중치를 시각화해서 필터가 무엇을 찾고 있는지 어떻게 알아요?!
이는 Templete Matchin이나 내적을 생각하면 된다고합니다. Templete Vector와 임의의 데이터를 내적에서 어떤 Scaler output을 계산하는데 필터값을 가장 활성화시키는 입력을 생각해보면 입력 값과 필터의 가중치 값이 동일한 경우입니다.
또한, 내적의 경우에는 내적 값을 최대화시키는 방법은 동일한 값 두 개를 내적하는 것입니다.
그러므로 이미지와 필터의 내적을 구한 첫 번째 레이어의 가중치를 시각화 시키면 첫 번째 레이어가 무엇을 찾는지 알 수 있는 것입니다.
 다음은 중간 과정에서의 시각화입니다.
다음은 중간 과정에서의 시각화입니다.
- Layer 1: 7x7 16개
- Layer 2: (input 16 channel 7x7) 20개
- Layer 3: (input 20 channel 7x7) 20개 Layer 2에서 시각화한 내용은 Layer 2의 결과를 최대화시키는(활성화시키는) 첫 번째 레이어의 출력 패턴이 무엇인지 입니다.
 마지막 레이어의 시각화입니다.
CNN의 마지막 레이어에는 1000개의 클래스 스코어가 있습니다. 바로 직전에는 4096-dim 특징 벡터를 갖고 있습니다.
마지막 레이어의 시각화입니다.
CNN의 마지막 레이어에는 1000개의 클래스 스코어가 있습니다. 바로 직전에는 4096-dim 특징 벡터를 갖고 있습니다.
- 많은 이미지를 CNN 돌림
- 각 이미지에서 나온 4096-dim 특징 벡터 저장
- Nearest Neighbors를 이용하여 시각화
Activations
Nearest Neighbors맨 왼쪽의 사진은 이미지 픽셀 공간에서의 Nearest Neighbors입니다.
픽셀 공간에서는 비슷한 형태나 색을 갖고 있다면 가깝다고 생각하는 것을 확인
4096-dim 특징 벡터를 이용해 계산한 Nearest Neighbors는 서로 픽셀값이 다르기도 하지만 특징을 중점으로 계산하기 때문에 픽셀 공간보다 잘 분류합니다.

차원 축소라는 단어를 생각하면 단연 제일 먼저 떠올리는 것은 PCA(Principle Component Analysis)일 것입니다. 고차원 특징 벡터들을 원하는 dimension으로 압축시키는 기법입니다.
PCA보다 더 강력한 알고리즘인 t-SNE(t-distributed stochastic Neighbor embeddings))입니다.
위 사진은 t-SNE를 이용해서 4096-dim 특징 벡터를 2-dim으로 압축한 사진입니다. 각각의 군집들이 특징별로 묶어져 위치해 있는 것을 알 수 있습니다.
How to visualize features
Maximally Activating Patches 어떤 이미지가 들어와야 각 뉴런들의 활성이 최대화되는지 시각화하는 방법
어떤 이미지가 들어와야 각 뉴런들의 활성이 최대화되는지 시각화하는 방법
- 채널 중의 하나를 지정(Channel 17)
- conv를 돌릴 때마다 지정한 채널의 값들을 저장
- 어떤 이미지의 일부분(Pathes)이 지정된 채널(특징 맵)을 최대로 활성화시키는지 확인
 입력의 어떤 부분이 분류를 결정짓는 근거가 되는지에 관한 실험
입력의 어떤 부분이 분류를 결정짓는 근거가 되는지에 관한 실험
- mask를 이용해서 이미지를 일부 가리고(가린 부분은 데이터셋의 평균값으로 채움)
- 네트워크가 이 이미지를 예측한 확률을 기록
- occluded(가림) patch 를 전체 이미지에 slide 예측확률이 낮을수록 해당 부분이 분류를 결정짓는 중요한 부분인 것을 알 수 있다.
 입력 이미지의 각 픽셀들에 대해 예측한
입력 이미지의 각 픽셀들에 대해 예측한 클래스 스코어의 그레디언트를 계산하는 방법
어떤 픽셀이 분류하는 데 있어서 어떤 픽셀들이 필요한지 알 수 있다
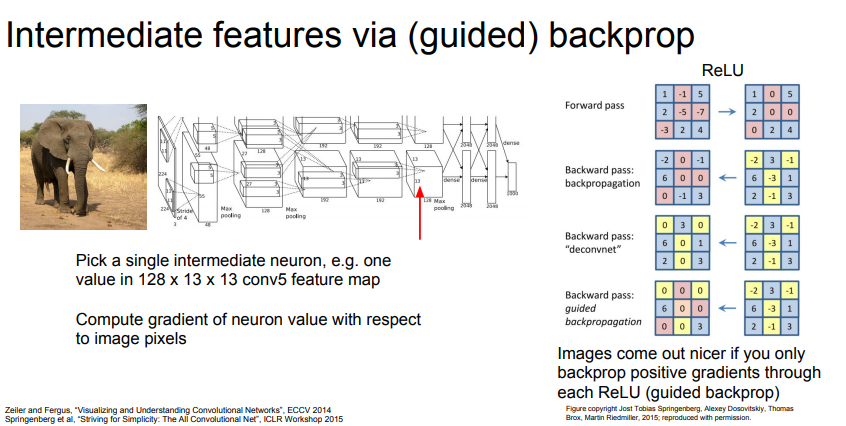
네트워크의 중간 뉴런을 하나 선택
입력 이미지의 어떤 부분이 내가 선택한 뉴런의 값에 영향을 주는지 찾는 것
즉, 입력 이미지의 각 픽셀에 대한 네트워크 중간 뉴런의 그레디언트를 계산
조금의 트릭을 이용해 더 깨끗한 이미지를 얻을 수 있다.= Gudied backprop
- ReLU의 그레디언트 부호가 양수면 그대로 통과
- 음수면 backprop를 하지 않음
위 두 가지 방법은 고정된 입력 이미지에 대한 연산을 수행할 뿐입니다.
해당 뉴런을 활성화시킬 수 있는 어떤 일반적인 입력 이미지가 있을까?
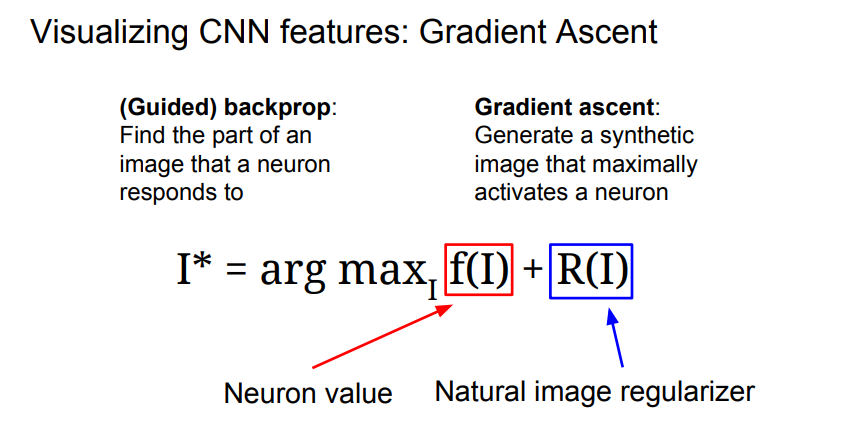 지금까지는 Loss를 최소화시켜 네트워크를 학습시키기 위해 Gradient decent를 사용했습니다.
지금까지는 Loss를 최소화시켜 네트워크를 학습시키기 위해 Gradient decent를 사용했습니다.
하지만 여기선 네트워크의 가중치를 모두 고정시킵니다. 그리고 Gradient ascent를 통해 중간 뉴런 혹은 클래스를 최대화시키는 입력 이미지의 픽셀들을 만들어냅니다.
여기서 Regularization term이 필요한데 기존에는 학습 데이터에 대해 과적합 방지용이었지만 여기서는 생성된 이미지가 특정 네트워크의 특성에 과적합 되는 것을 방지합니다. 특성
- 이미지가 특정 뉴런의 값을 최대화시키는 방향으로 생성
- 이미지가 자연스러워 보여야 함
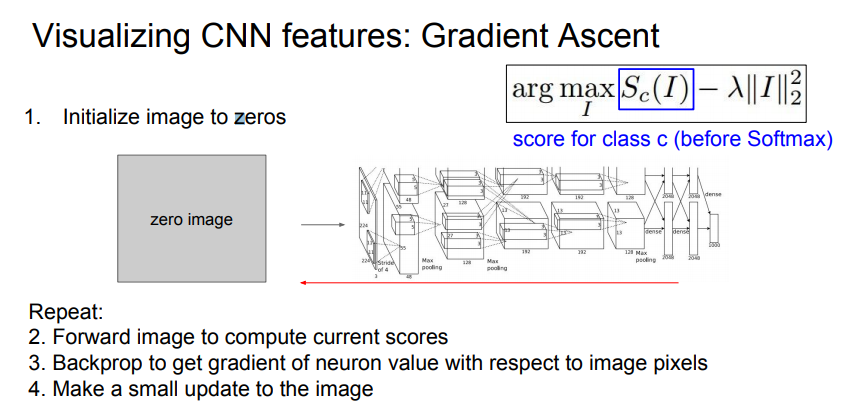
- initialize image가 필요(Zeros, uniform, noise 등으로 초기화)
- 이미지를 네트워크에 통과, 관심 있는 뉴런 스코어 계산
- 이미지 각 픽셀에 대한 해당 뉴런 스코어의 그레디언트를 계산하여 backprop 진행
- Gradient ascent로 업데이트
 여기서 간단히 L2 norm을 사용(딱히 의도는 없음)
스코어를 최대화시키는 이미지 사진을 보면 각각의 다양한 물체가 중첩되어 있는 것을 볼 수 있습니다.
여기서 간단히 L2 norm을 사용(딱히 의도는 없음)
스코어를 최대화시키는 이미지 사진을 보면 각각의 다양한 물체가 중첩되어 있는 것을 볼 수 있습니다.
 조금 더 괜찮은 Regularization으로 이미지를 깔끔하게 만들 수 있습니다.
조금 더 괜찮은 Regularization으로 이미지를 깔끔하게 만들 수 있습니다.
- 기본적인 L2
최적화 과정 중
- 주기적으로 가우시안 블러를 적용
- 주기적으로 값이 작은 픽셀들을 모두 0으로 만듦
- 낮은 기울기의 픽셀값 중 일부는 0으로
생성된 이미지를 더 좋은 특성을 가진 이미지 집합으로 주기적으로 매핑시키는 방법
이 방법은 최종 클래스 스코어뿐만 아니라 중간 뉴런에 대해서도 가능합니다.
이미지 생성 문제에서 사전 지식(priors)을 추가하게 된다면 아주 리얼한 이미지를 만들어 낼 수 있습니다. (with feature inversion network)

이미지 픽셀의 그레디언트를 이용해 이렇게 이미지를 합성하는 강력한 방법
이미지를 속이는 것!
임의의 이미지를 선택한 후, 다른 이미지의 점수를 최대화합니다.
코끼리의 사진에 코알라의 점수를 최대화하기 위해 코끼리 이미지를 조금씩 코알라로 바꾸다 보면 네트워크는 코끼리 사진을 코알라로 분류합니다
- (1) Start from an arbitrary image
- (2) Pick an arbitrary class
- (3) Modify the image to maximize the class
- (4) Repeat until network is fooled
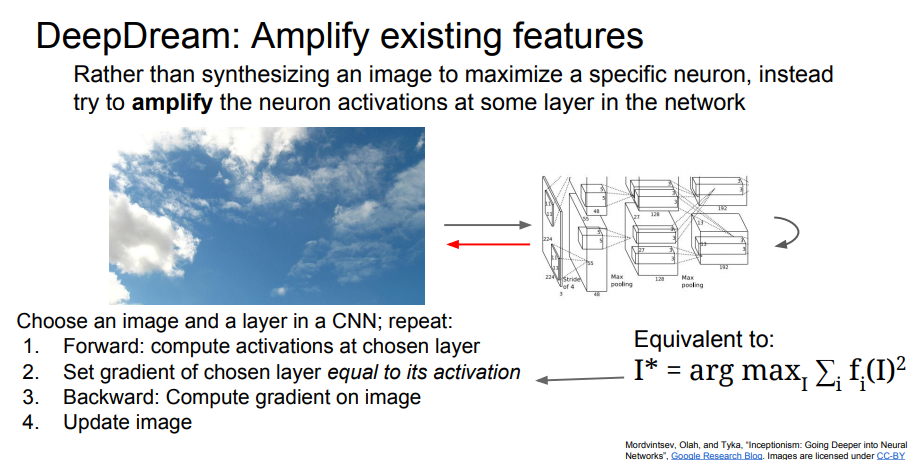
과학적 가치의 측면에서 보자면 단순히 재미만을 위한 것입니다. 똑같이 입력 이미지를 네트워크에 통과시키고 backprop할 때 해당 레이어의 그레디언트를 Activation값으로 설정합니다. 이는 네트워크에 의해 검출된 이미지의 특징들을 증폭시키려는 것으로 해석할 수 있습니다. 왜냐하면, 해당 레이어에 어떤 특징들이 있던지 그 특징들을 그레디언트로 설정하면 이는 네트워크가 이미지에서 이미 뽑아낸 특징들을 더욱 증폭시키는 역할을 하는 것입니다. 또한, L2 norm을 통해 레이어의 특징을 최대화시킵니다.
1/(x^2)가 있을 때 activation에 대한 그레디언트는 x입니다. 따라서 그레디언트를 보낼 때 activation값 자체를 보내게 되면 1/(x^2)의 그레디언트를 계산하는 것과 동치입니다. 해당 레이어의 특징들(activations)의 norm을 최대화시키는 것과도 동치입니다. 하지만 실제 구현은 이를 명시적으로 계산하지 않고 그레디언트만 뒤로 보내줍니다.

- Jitter image 이미지를 조금씩 움직이는 트릭 Regularizer 역할을 해서 부드러운 이미지를 만들어줍니다.
- L1 norm 이미지 합성에서 아주 유용함
- Clipping 이미지가 존재할 수 있는 공간으로 매핑시키는 방법
- Result
 ‘개’가 많이 보이는 이유는 이 네트워크가 Image Net의 1000개의 카테고리를 학습한 네트워크인데 그중 200개가 ‘개’라서 많이 보이는 것입니다.
‘개’가 많이 보이는 이유는 이 네트워크가 Image Net의 1000개의 카테고리를 학습한 네트워크인데 그중 200개가 ‘개’라서 많이 보이는 것입니다.
 MIT place로 학습시킨 네트워크입니다.
멀티 스케일 프로세싱을 수행해서 작은 이미지로 Deep Dream을 수행하고 점점 이미지 크기를 늘리고 최종 스케일에서 앞의 과정을 반복해서 만듭니다.
MIT place로 학습시킨 네트워크입니다.
멀티 스케일 프로세싱을 수행해서 작은 이미지로 Deep Dream을 수행하고 점점 이미지 크기를 늘리고 최종 스케일에서 앞의 과정을 반복해서 만듭니다.

이 방법 또한 다양한 레이어에서 이미지의 어떤 요소를 포착하고 있는지 짐작할 수 있게 도와줍니다.
네트워크를 통과하며 나온 특징(activation map)을 저장해둡니다. 그리고 이 특징을 이용해서 이미지를 재구성할 텐데요.
해당 레이어의 특징 벡터로부터 이미지를 재구성해보면, 이미지의 어떤 정보가 특징 벡터에서 포착되는지를 짐작할 수 있을 것입니다.
Point
- 스코어 최대화 대신 특징 벡터 간의 거리를 최소화(기존 계산해둔 거와 생성한 이미지로 계산한 특징 벡터)
- toal variation Regularization
상하좌우 인접 픽셀 간의 차이에 대한 패널티 부여
 처음 이미지가 들어오고서는 재구성했을 때 원본과 거의 차이점이 없지만, 네트워크를 통과하면서 주요 특징은 남지만, 저수준의 정보(디테일,텍스쳐,색, 등)들이 사라지는 것을 볼 수 있습니다
처음 이미지가 들어오고서는 재구성했을 때 원본과 거의 차이점이 없지만, 네트워크를 통과하면서 주요 특징은 남지만, 저수준의 정보(디테일,텍스쳐,색, 등)들이 사라지는 것을 볼 수 있습니다

문제는 input 패치가 있을 때, 동일한 텍스처인 더 큰 패치를 생성하는 것입니다.
이러한 텍스처 합성은 Computer Graghics에서는 아주 오래된 문제입니다.
Nearest Neighbor도 잘 되며 신경망 대신 scan line을 따라서 한 픽셀씩 이미지를 생성해 나가는 방식입니다.
- 현재 생성해야 할 픽셀 주변의 이미 생성된 픽셀들을 살펴보기
- 입력 패치에서 가장 가까운 픽셀을 계산
- 입력 패치로부터 한 픽셀을 복사해 넣는 방식
자세히 알 필요는 없어요~
하지만 복잡한 텍스처에서는 단순히 복사하는 것으로는 문제를 풀 수 없을 수도 있습니다.
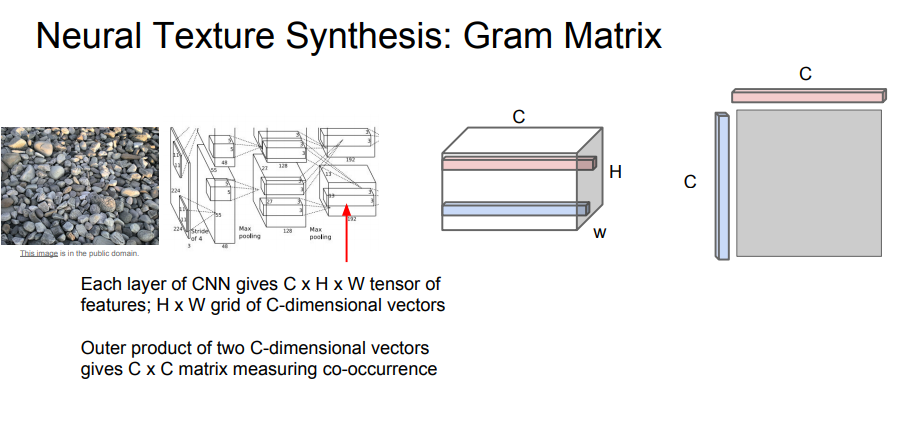
- 입력 이미지 네트워크 통과
- 특정 레이어에서 특징 맵(Activation Map) 가져오기(CxHxW)
- 특징 맵을 갖고 입력 이미지의 텍스처 기술자(descriptor)를 계산
- 특징 맵에서 서로 다른 두 개의 특징 벡터를 뽑기(빨, 파)
- 두 벡터의 외적을 계산 CxC 행렬 만듦 이 CxC행렬은 이미지 내 서로 다른 두 지점에 있는 특징 간의 co-occurrence를 담고 있다
서로 다른 공간에서 동시에 활성화되는 특징이 무엇인지 2차 모멘트를 통해 어느 정도 포착 가능합니다.
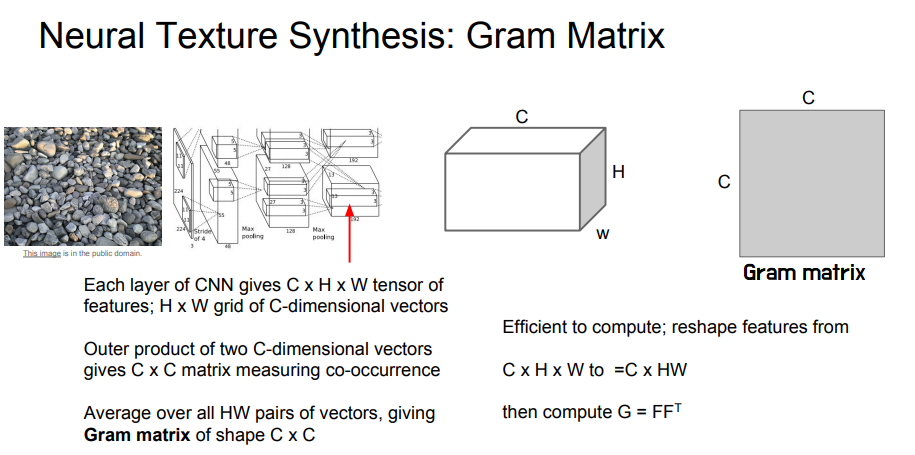 위 과정을 HxW 그리드에서 전부 수행하고 결과에 대한 평균을 계산하면 CxC Gram matrix를 얻을 수 있습니다.
위 과정을 HxW 그리드에서 전부 수행하고 결과에 대한 평균을 계산하면 CxC Gram matrix를 얻을 수 있습니다.
이 Gram matrix를 입력 이미지의 텍스처 기술자로 사용합니다.
- 공간 정보를 모두 날려버림
이미지의 각 지점 값들을 평균화해버렸기 때문이다. 대신 co-occurrence를만을 포착하고 있습니다.
물론 공분산으로도 계산할 수 있지만, 계산 비용이 너무 크다는 단점이 있습니다.
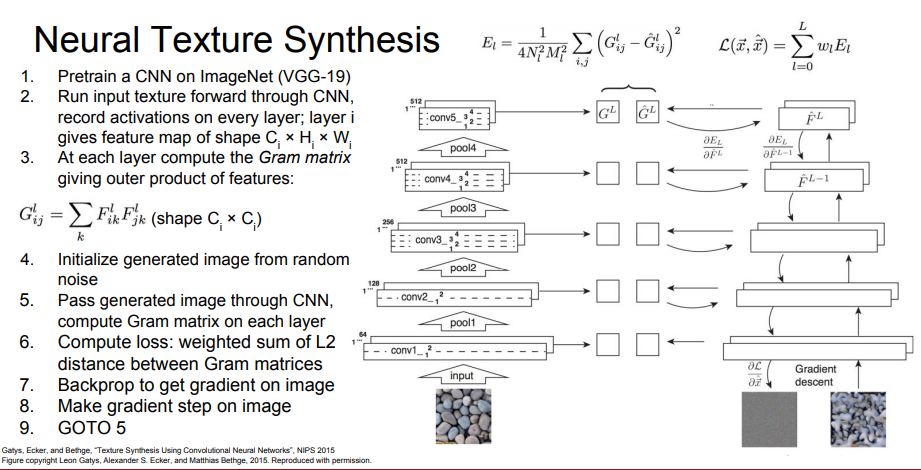 Gradient ascent procedure과 유사한 과정입니다.
Gradient ascent procedure과 유사한 과정입니다.
- pretrained 모델 내려받기(VGG를 선호한다고 해요)
- input image를 CNN을 통과시키며 모든 레이어의 activations를 기록 Layer_i는 \C_i\times H_i\times W_i(\) 의 쉐입
- 각각의 레이어에서 Gram matrix를 계산
- 생성해야 할 이미지를 랜덤으로 초기화
- 다시 CNN에 generated image를 통과시키며 Gram matrix를 계산
- 원본 이미지와 생성된 이미지의 Gram matrix 간의 차이를 L2 norm을 이용해 Loss로 계산
- backprop를 통해 생성된 이미지의 픽셀의 그레디언트를 계산
- Gradient ascent를 이용해 이미지의 픽셀을 업데이트
- 5단계로 돌아가 버려! (여러 번 반복)


앞서 배운 두 가지 Texture Synthesis와 Feature reconstruction을 합친 것입니다.
입력으로 2가지가 들어갑니다.
- Content Image : 최종 이미지가 이렇게 생겼으면 좋겠어!
- Style Image: 이런 분위기(스타일)로 만들어줘!
Style Transfer는 Content 이미지의 feature reconstruction loss와 style 이미지의 gram matrix loss도 최소화하는 방식으로 최적화하여 생성합니다.
네트워크에 두 가지 input을 넣고 gram matrix와 feature map을 계산
최종 출력 이미지는 랜덤 노이즈로 초기화
forward/backprop 과정에서 Gradient ascent로 업데이트를 수백 번 반복하면 끝!
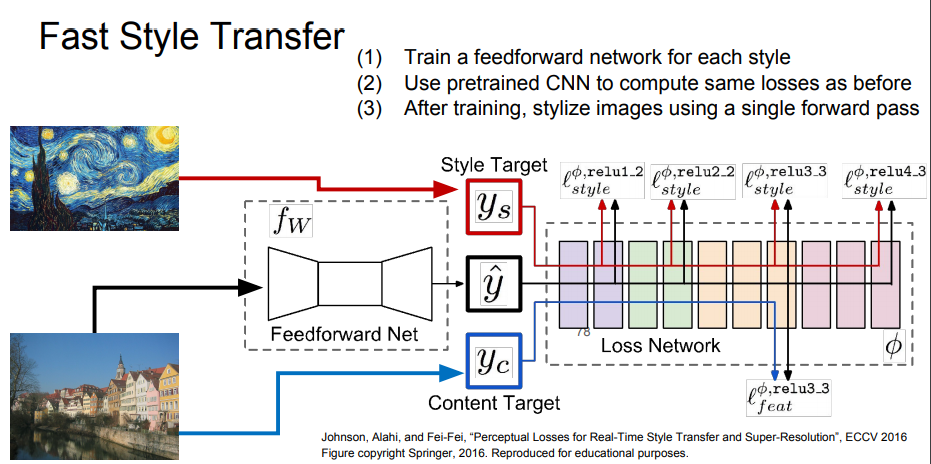
4K 이미지를 만드는 건 계산 비용이 너무 많이 들어가고 forward/backward를 수백 번 반복해야 하는 문제점이 있습니다.
즉 너무 느리다는 건데 이 문제점을 해결하는 방안으로 Style Transfer를 위한 또 다른 네트워크를 학습하는 것입니다.
- Style 이미지를 고정
- Content 이미지만을 입력으로 받아서 결과를 출력하는 단일 네트워크를 학습
학습 시에는 content/style loss를 동시에 학습 네트워크 가중치 업데이트합니다.
학습은 좀 오래 걸리지만 한 번 학습을 시키고 나면 이미지를 네트워크에 통과시키면 결과를 바로 볼 수 있다.

 Google에서 나온 논문으로 하나의 네트워크로 다양한 Style을 생성해내는 방법
Google에서 나온 논문으로 하나의 네트워크로 다양한 Style을 생성해내는 방법
 style blending도 가능 서로 다른 스타일을 학습하면서 섞기
style blending도 가능 서로 다른 스타일을 학습하면서 섞기