[cs231n] 11강 리뷰
Segmentation && Detection

Tip: 이미지를 클릭하시면 바로 유튜브 강의를 볼 수 있습니다.
앞서 Classification과 다양한 모델들 그리고 아키텍처들을 살펴봤습니다. 이번 강의에서는 Computer Vision분야의 다른 task들을 알아볼 것입니다.
Today topic
- Semantic Segmentation
- Instance Segmentation
- Classification + Localization
- Object Detection
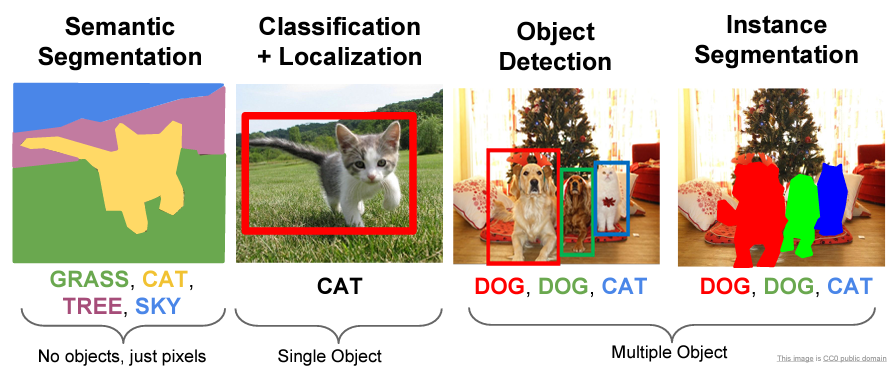
Semantic Segmentation

Semantic Segmentation은 이미지의 픽셀들이 어떤 클래스에 속하는지 예측하는 과정이다. 예를들어 위 사진 처럼 각각의 픽셀이 고양이인지 잔디인지 하늘인지 예측하여 맞춰야한다.
하지만 문제점이 하나 있다면 개별 객체는 구분을 못한다..(우측 소 사진 참고)
IDEA 1: Sliding Window
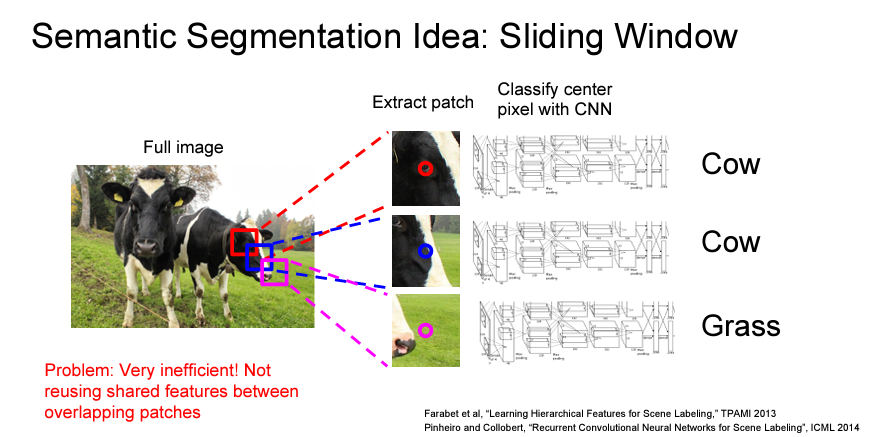
- Patch를 만들고, 사진의 전체를 모두 돌면서 한 픽셀이 어느 클래스에 들어가는지 예측하는 방법
- 이 방법은 computation이 비쌉니다. 딱 봐도 계산량이 어마무시할 것으로 예상됩니다
- 또한 겹쳐지는 Patch의 공유된 feature들을 재사용하지 않는 문제점이 있습니다.
- 추후 instance segmentation에서 이 문제를 해결할 예정입니다.
IDEA 2: Fully Convolutional Networks
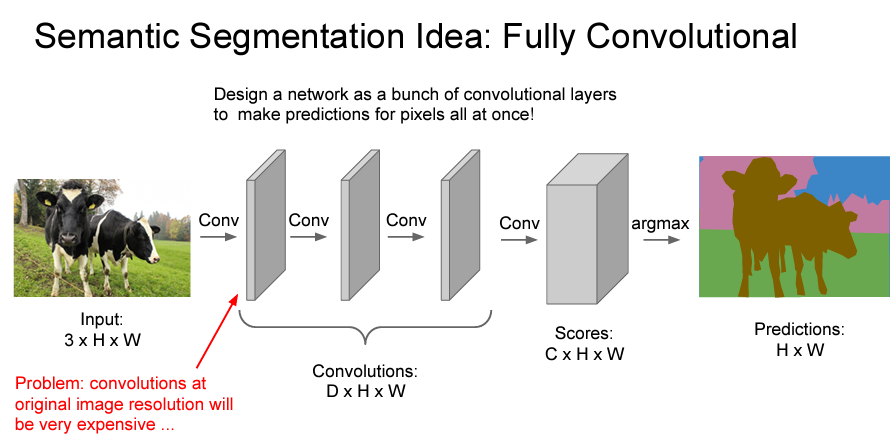
- 3x3 filter를 사용해 이미지 크기를 유지하며 convolution에 넣음
- 한번에 모든 픽셀을 예측할 수 있도록 설계
- 원본 이미지 크기를 유지하면서 진행하기 때문에 연산량이 매우 높다는 문제점
Fully Convolutional with Downsampling and Upsampling
그 동안의 문제점을 보완하기 위해 나온 구조입니다.
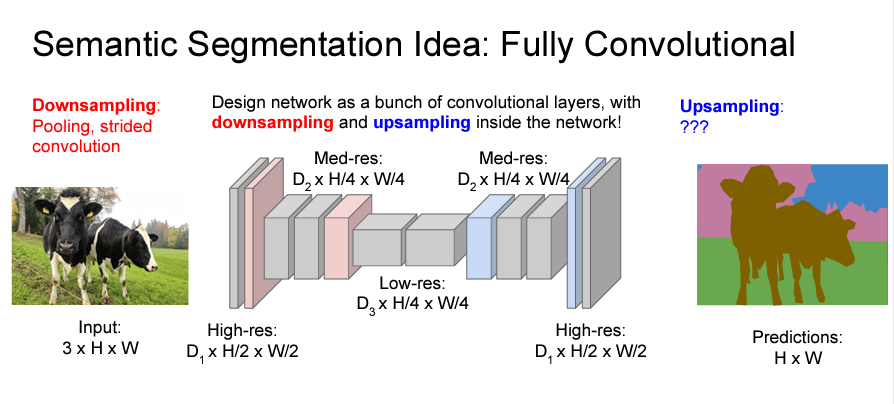
Downsampling 후에 다시 Upsampling을 해서 다시 원본처럼 만들어주는 방법인데 문제가 하나 있습니다.
다시 이미지의 사이즈를 늘릴 때 빈공간을 어떻게 채울것인가..?
Nearest Neighbor 매우 1차원적인 방법으로 빈공간을 원래 있던 값으로 모두 채우는 방법이다.
Bad of Nails unpooling region에만 값을 채우고 나머지는 0으로 채움
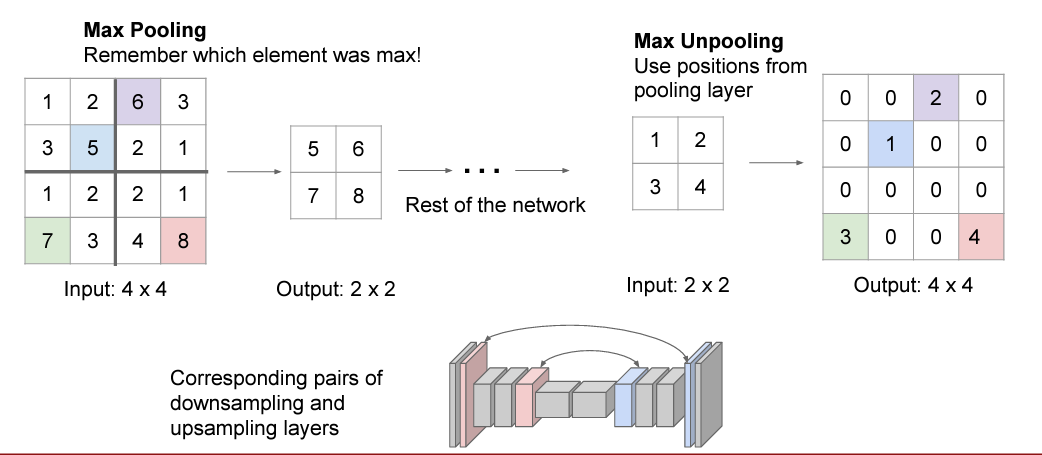
Solution 2: Max unpooling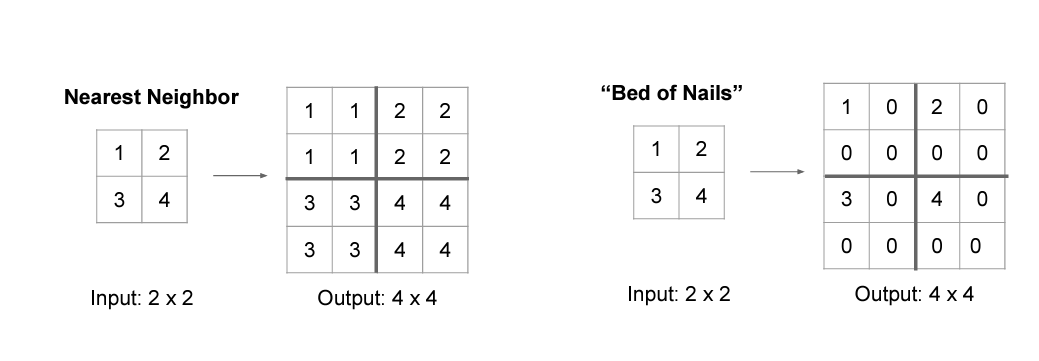
네트워크는 대칭적인 경향이 있는데 각 pooling과 unpooling을 연괏짓는 방법입니다.
Max pooling시에 선정된 Region을 기억하고 있다가 unpooling할 때 해당 Region에 값을 채우고 나머지는 0으로 통일합니다.
하지만 특정 Feature Map의 공간성을 잃는다는 단점이 있다
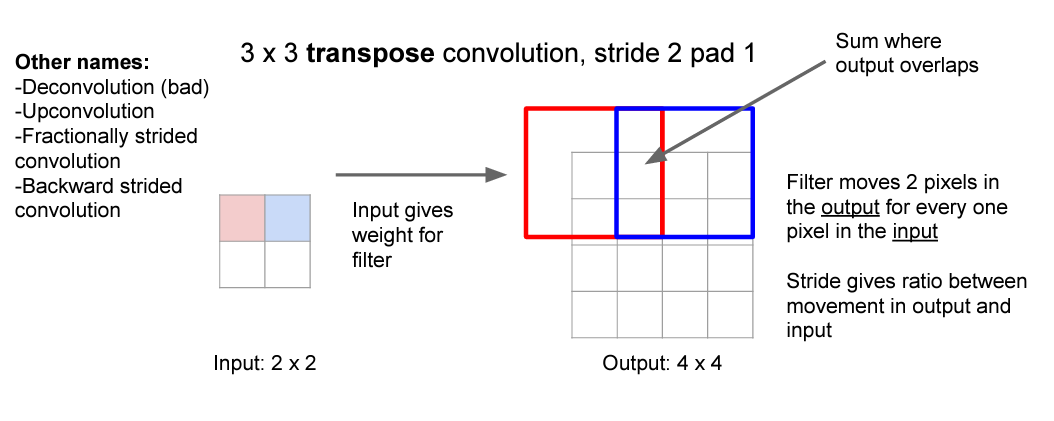
위 그림은 일반적인 3x3 Conv입니다. stride=2 pad=1
filter는 2 pixels 움직여 output에 값을 채워주게 됩니다.
이 때 중요한 점은 입력값과 출력값 사이에 위치 정보가 연결되어 있습니다.
Transpose convolutional은 이 방식을 거꾸로 한다고 생각하시면 편합니다.
똑같이 필터를 움직이며 input의 모든 값을 채워 넣습니다.
output에서는 transpose convolution간에 Receptive Field가 겹칠 수 있습니다.
여기서 특이하게 겹치는 부분은 덧셈을 하게되는데 수식이 그렇게 되어 있으며 Receptive Field의 크기에 따라 magnitudes가 달라지는 문제가 될 수 있습니다.
아직 이부분은 연구가 진행중이라고 합니다.
행렬곱으로 보면 조금 더 이해가 잘 된다고 하네요..
1D로 된 convolutiond으로 예시를 들어보겠습니다.

- Stride= 1
- Padding =1
Xa가 만들어지는 것 까지는 오케이!
Ta도 오케이! normal과 비슷하게 나옵니다.
하지만 stride가 2일 경우에는?

stride가 1보다 큰 경우에는 더이상 convolution이 아니라고 설명합니다.
stride 2 T convolution은 이제 normal과 근본적으로 다른 연산이 되기 때문입니다.
output이 input에 비해 크게 확장된 것을 알 수 있습니다.
이제 downsampling과 upsampling 후 모든 픽셀에 대한 cross-entropy를 계산하면 전체 네트워크를 end-to-end로 학습시킬 수 있습니다.
Classification + Localization
이미지가 어떤 카테고리에 속하는지 뿐만 아니라 실제 객체에 Bounding Box(네모)를 그려서 이미지에서 어디에 있는지 알 수 있습니다.
Classification + Localization은 object detection과는 구별됩니다.
localization에서는 오직 하나의 객체만 찾아 레이블을 매기고 위치를 찾습니다.
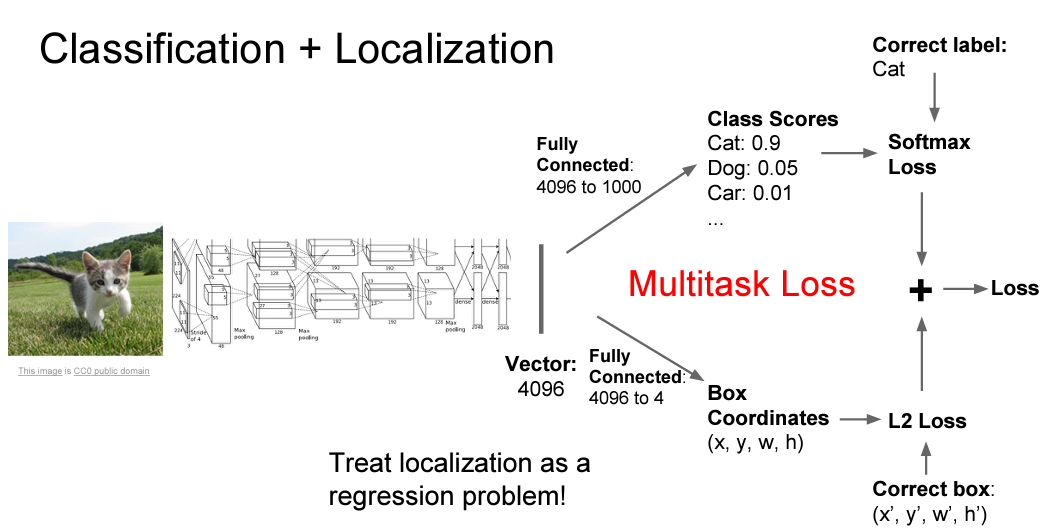
- input: 이미지
- output1: Class Scores(Softmax loss)
- output2: Bbox 좌표(예측한 Bbox와 실제 Bbox의 차이 측정 loss like L2)
학습시에 loss가 두 개가 존재합니다. (지도 학습 가정)
학습 이미지에는 카테고리 레이블과 해당 객체의 Bbox를 동시에 가지고 있어야 합니다.
Q: 왜 두 loss를 동시에 학습시키나요? 오분류에 대해 Bbox가 있으면 어떻게 되나요?
A: 일반적으로 괜찮습니다. 오분류의 문제에서 까다로울 수 있음. Bbox를 카테고리마다 하나씩 예측해서 Ground Truth 카테고리에 속한 예측된 Bbox에만 Loss를 연결시킵니다. 실제로 아주 유용합니다.
Q: 두 개의 loss 단위가 다른데 Gradient 계산시 문제가 되지 않나요?
A: multi-task loss입니다. 네트워크 가중치들의 각각의 미분 값을 계산해야 합니다. 그래서 두 개의 미분값이 생기고 둘 다 최소화 시켜야합니다. 사실 이 loss의 가중치를 조절하는 하이퍼 파라미터가 있습니다. 두 loss의 가중치 합이 최종 loss입니다. loss의 가중치 합에 대한 gradient를 계산하는 것입니다.
이 하이퍼 파라미터를 튜닝하는 것은 어려운데 그 이유는 이전에 봐왔던 것과는 다르게 이 하이퍼 파라미터는 loss값 자체를 변경하게 됩니다. 일반적인 방법은loss값을 비교하는 것이 아니라 모델의 성능지표를 보는 것입니다.
Q: 앞쪽 큰 네트워크만 고정시키고 각 FC-layer만 학습시키는건 어떤가요?
A: 괜찮은 방법입니다. transfer learning의 관점에서 보면 fine tune을 하는것이 성능 향상에 더 도움됩니다. 실제로 사람들이 많이 하는 방법은 네트워크를 Freeze하고(동결시켜서 W가 학습되지 않음) 두 FC-layer를 학습시킵니다. 그 후 FC-layer가 수렴하면 전체 네트워크를 Fine tune!
Object Detection
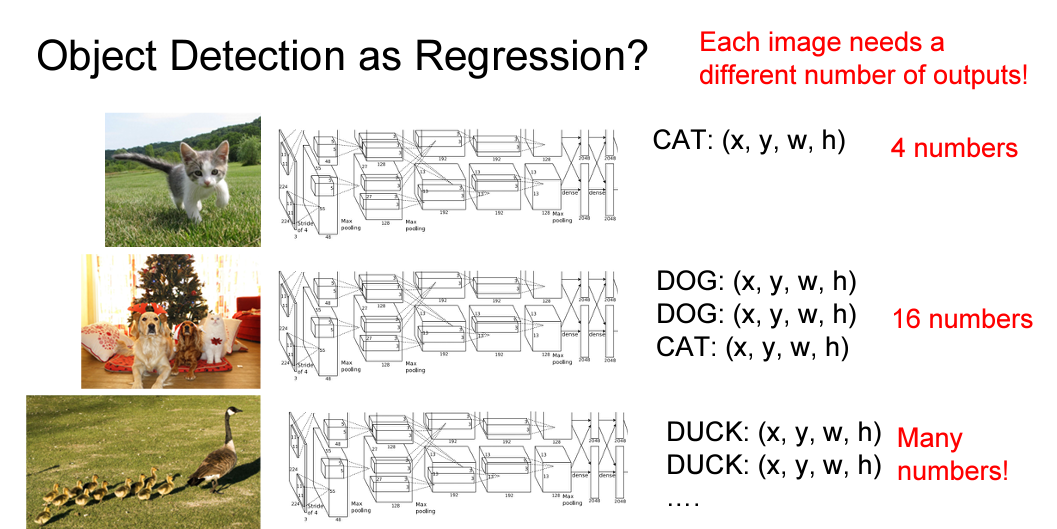
방금 본 Classification + Localization과 비슷하게 보이지만 큰 차이가 있습니다.
Object Detection은 입력 이미지의 객체 수를 알지 못합니다. input image에 따라 다른 output이 나옵니다. 따라서 Regression로 풀기 상당히 어렵습니다.
IDEA 1: Sliding Window

Sementic Segmentation에서 봤던 것과 유사합니다.
crop(잘라낸)한 이미지를 CNN에 넣고 classification을 돌립니다 객체가 있는지 없는지 그 객채가 Dog인지 Cat인지 확인합니다.
그 후 Background 카테고리를 추가해줍니다. 나중에 Bbox를 그릴 때 Background에 속한 것들은 제외됩니다.
게다가 input image에 Objects가 몇 개가 존재할지 어디에 있을지 모릅니다.
이러한 문제 때문에 Sliding Window를 할려면 너무나도 많은 경우의 수가 존재합니다.
IDEA 2: Region Proposals

사실 이 방법은 Deep learning을 사용하지는 않습니다.
이미지 내에 뭉쳐진 곳들을 찾아 Object가 있을법한 1000개의 box를 제공합니다.
이 지역들은 객체가 있을지도 모르는 후보 영역들입니다.
Selective Search
2000개의 Region Proposals을 만들어 냅니다. 비교적 빠릅니다. 노이즈가 심하고 실제 객체가 아닐수도 있지만 꽤 괜찮습니다.
이제는 모든 위치를 다 고려하는 것이 아니라 Region Proposals Networks를 적용해서 객체가 있을법한 Region Proposals를 얻어냅니다. 이것을 CNN의 입력으로 넣으면 이전 방법보다 훨씬 계산량을 감소시킬 수 있을 것입니다.
R-CNN에서 나온 내용입니다.
R-CNN
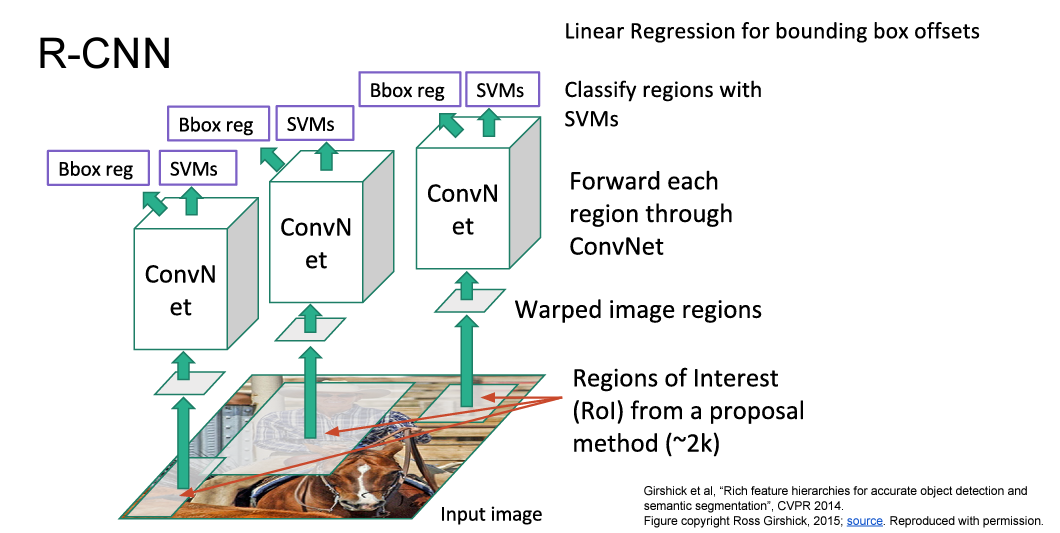
- Region Proposals Network 수행
- Selectiv Search 수행 2000개 ROI(Region of Interesting=Region Proposals) 획득
- ROI 사이즈 동일하게 resize
- 각각 ROI CNN 수행
- 최종 Classification SVMs 수행
문제점
- 계산 비용이 많이 든다.
- 용량(Memory)도 많이 든다.
- 학습 과정도 느리다. (논문 기준 81시간)
- Test Time도 느리다. (한 이미지당 30초)
- 학습이 되지 않는 Region Proposal이 존재
- Backprop가 안된다.
Fast R-CNN
앞서 R-CNN은 다양한 문제점이 있었습니다. 해당되는 문제점들 중에서 속도 측면에서 더 빨라진 모델입니다.
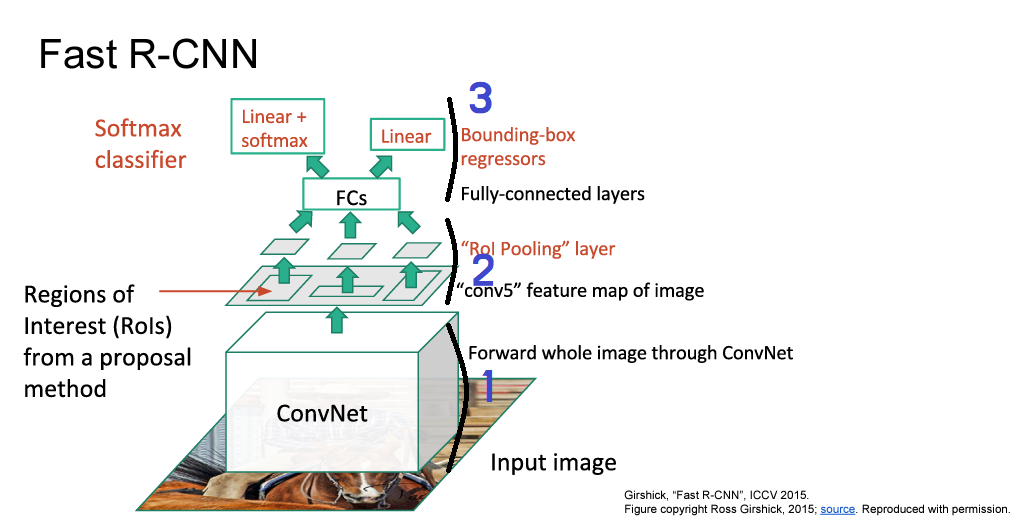
기존 모델은 이미지에서 바로 Selective Serch를 통해서 각각의 Region proposals를 CNN에 넣고 작업 시간을 오래 잡아먹었습니다.
하지만 Fast R-CNN 모델은 먼저 이미지에서 ROI 영역 추출 후 CNN을 거쳐서 Feature Map을 뽑고 거기에 처음에 뽑아둔 ROI영역을 적용 시키기 때문에 Feature들을 공유하면서 더 빠르게 작업을 수행할 수 있습니다. 즉, input이 R-CNN은 2000장 정도였다면 현재는 1장입니다.
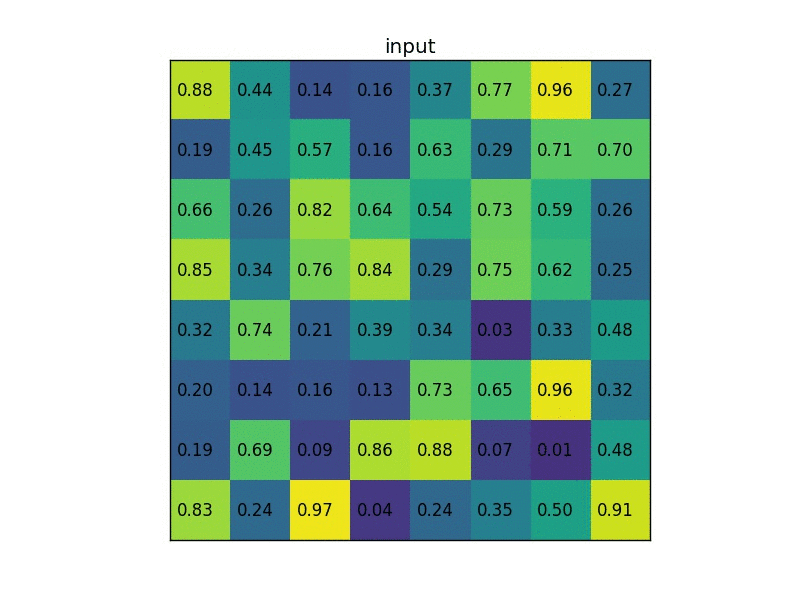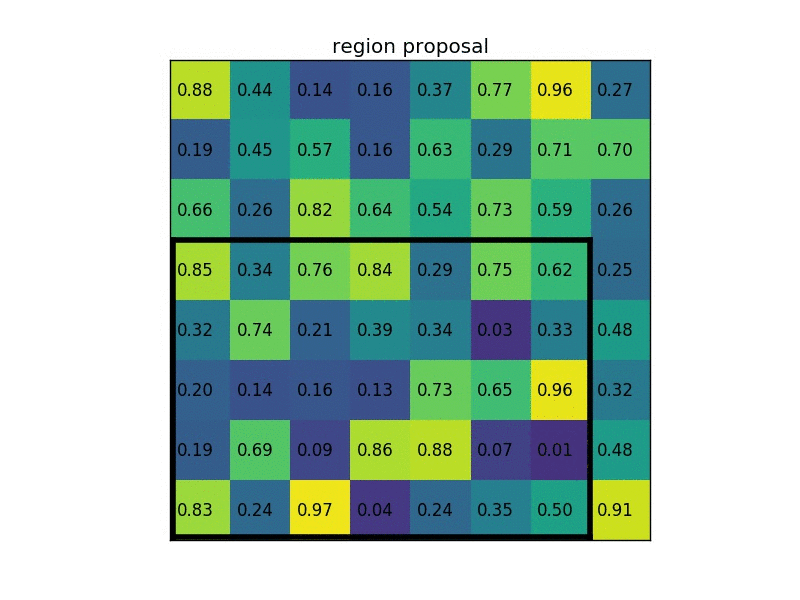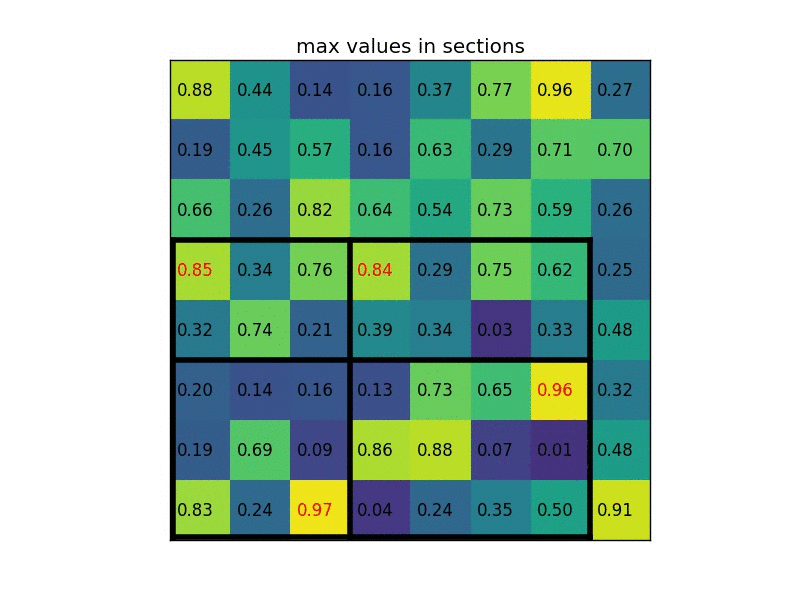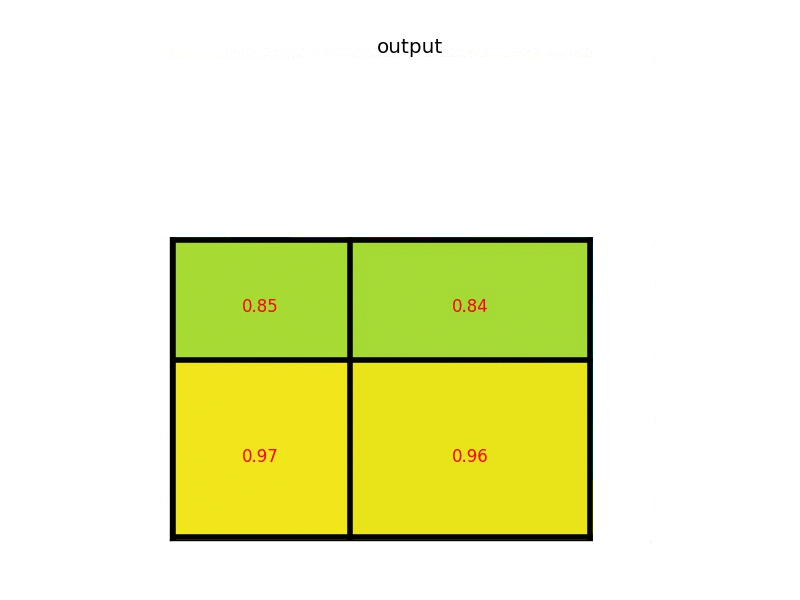
ROI Pooling
이 부분은 Fast R-CNN의 핵심이라고 할 수 있습니다. ROI를 FC layer에 넣기 위해서는 같은 크기여야 하는데 Selective Search를 통해 구해진 ROI 영역은 제각각 다릅니다. 따라서 이 Resolution의 크기를 맞춰주기 위해 ROI pooling을 수행합니다.
간단하게 FC layer에 넣기 위해 제각각인 모양을 통일시켜준다고 생각하시면 됩니다.
그 방법은 크기가 다른 Feature Map의 Region마다 Stride를 다르게 Max pooling하는 것입니다.
마지막 부분은 R-CNN과 비슷하지만 softmax를 사용해서 classification을 진행 했습니다.
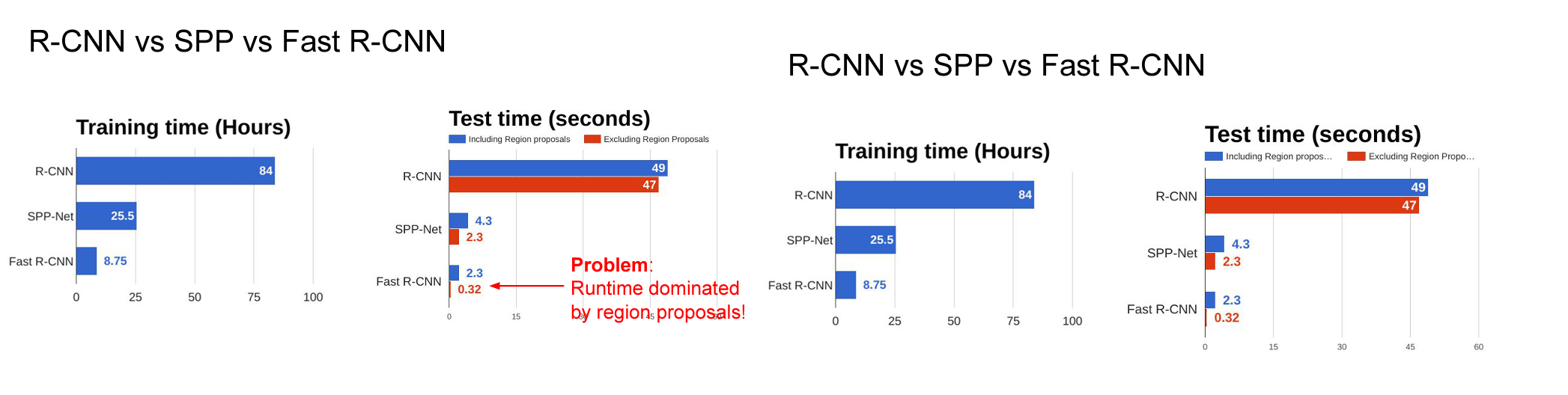 R-CNN이나 SPP-Net에 비해 뛰어난 성능을 보였고 기존 R-CNN의 문제도 많이 해결했지만 Region Proposal에 걸리는 2.3초 중 2초의 시간 때문에 병목현상이 생기는 문제가 있지만 그것을 해결하기 위해 아래 모델이 나왔습니다.
R-CNN이나 SPP-Net에 비해 뛰어난 성능을 보였고 기존 R-CNN의 문제도 많이 해결했지만 Region Proposal에 걸리는 2.3초 중 2초의 시간 때문에 병목현상이 생기는 문제가 있지만 그것을 해결하기 위해 아래 모델이 나왔습니다.
Faster R-CNN
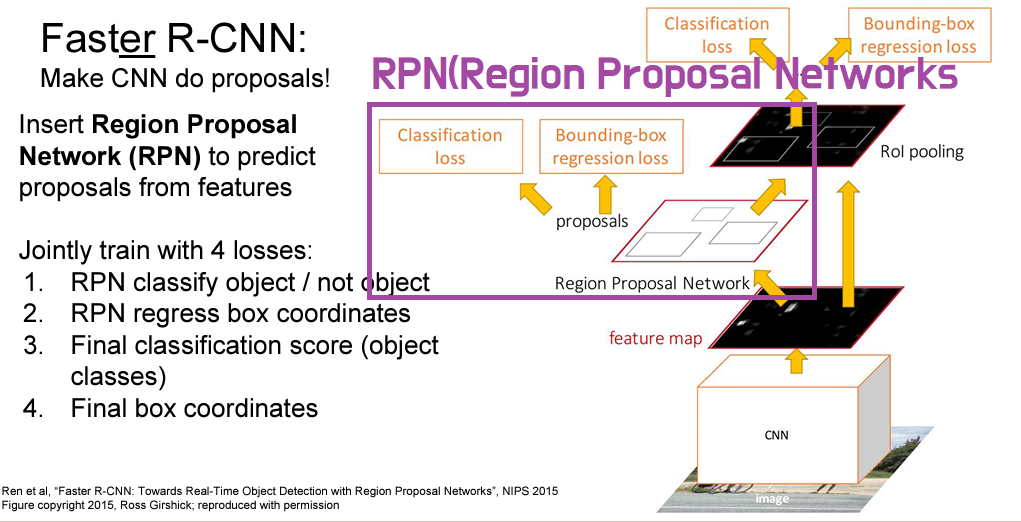
다른 부분들은 다 비슷하지만 여기에 RPN이라는 개념이 나옵니다. 해당 보라색 부분과 Selective Search를 제외하면 동일한 구조입니다. RPN의 input은 Feature map이고 output은 Object proposals의 Sample입니다.
원래 네트워크 밖에서 Selective Search를 하며 2초가 걸렸던 것을 이제 네트워크 안에서 RPN이 해결합니다.
총 4개의 Loss function이 필요합니다.
- RPN classify object / not object (binary classificaion) ROI에 객체가 있는지 없는지
- RPN regress box coordinate 예측한 BBox에 관한 것
- Final classification score(object classes)
- Final box coordinates 앞서 만든 regression을 보정해줍니다
RPN은 Region Proposal Network을 의미한다. Faster R-CNN에서는 총 9개의 anchor box를 사용하는데
Anchor box란 물체의 모양이 어떻게 생겼는지 모르니 서로 다른 비율의 Bounding Box를 만들고, 모두 시도를 해봐서 최적의 Bounding Box를 찾기 위해 사용하는 것이라 생각하면 이해하기 쉽다.
물체가 있을 확률을 IoU(Intersection over Union)을 통해 계산한다.
내가 예측한 Boundnig Box의 크기와 실제 Groundtruth의 값을 비교해보는 것이다.
Q: 어떻게 RPN GT가 없는데 어떻게 RPN을 학습시키는가?
A:
GT(Ground truth) object와 일정 threshold이상 겹치는 proposals이 있을 것입니다. 이런 regoin proposal은 positive라고 예측해야 합니다. 반면 조금만 겹치면 Negative라고 예측해야합니다.
Faster R-CNN에서 흥미로운 점은 Region proposals 자체도 학습되었기 때문에 RPN과 새로운 데이터 사이의 간극이 존재할 수도 있을 것입니다. 이 경우에는 새로운 데이터에 맞게 region proplosal을 새롭게 학습시키면 그만입니다.
Yolo/SSD
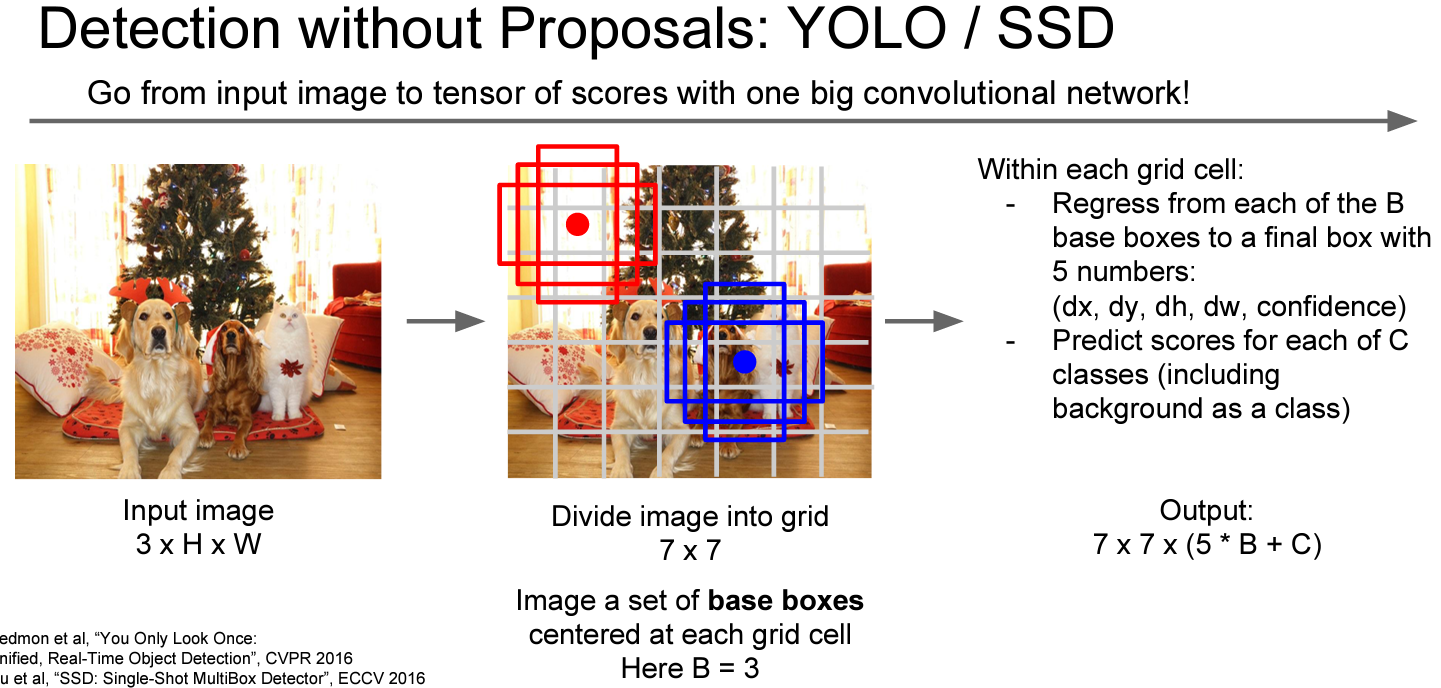
그림 우측의 B는 base BBox의 offset(4개) + Confidence score(1개)로 구성
C는 C개의 카테고리에 대한 Classification Score
지금까지는 2-stage Detector였습니다 classificaion과 localization을 따로 했지만 Yolo와 SSD는 한 번의 forward pass로 처리합니다.
주요 아이디어는 각 Task를 따로 계산하지않고 하나의 regression문제로 풀어보는 것입니다.
거대한 CNN을 통해서 예측을 할텐데 그 결과값 중 하나는 Bbox의 offset을 예측할 수 있을 것입니다. 실제 위치가 되려면 base BBox를 얼만큼 옮겨야 하는지를 뜻합니다. 그리고 각 BBOx에 대해서 Classification Score를 구합니다. 이 카테고리에 속한 객체가 존재할 가능성을 의미합니다.
You Only Look oneYolo같은 경우는 이미지의 Grid를 나눌 때 7*7로 고정을 한 다음, Bounding Box를 찾습니다
Single Short Detection후보 base BBox와 GT Objects를 매칭시키는 방법
SSD의 같은 경우 Grid를 나눌 때, 여러 feature map을 참고하여 세분화하여 Grid를 나누고 Bounding Box를 찾는다.
Instance Segmentation
위에서 배운 것들의 총 집합입니다. 각각의 객체를 찾아서 BBox를 그리는게 아니라 객체 별 Segmentation Mask를 예측해야합니다. 각 객체에 해당하는 픽셀을 예측해야 하는 문제입니다.
Mask R-CNN
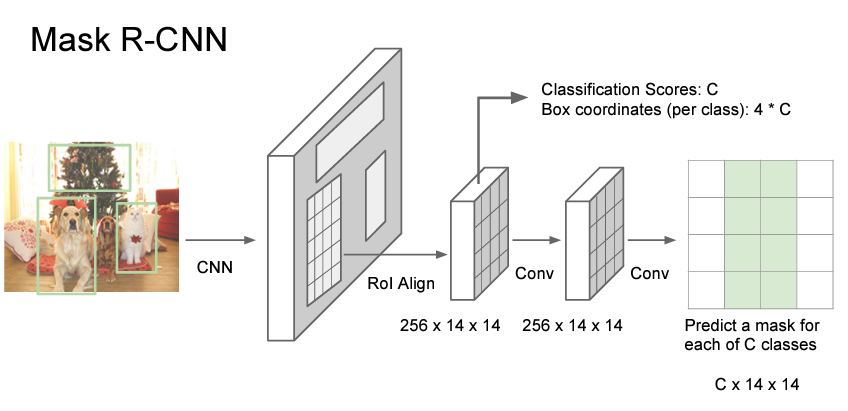
Faster R-CNN와 유사합니다. ROI Align(Pooling)까지는 동일하지만 거기서 BBox마다 Segmentation mask를 예측하도록 합니다.
RPN으로 뽑은 ROI영역 내에서 각각 sementic segmentation을 수행합니다.
위쪽으로는 각 Region proposal이 어떤 카테고리에 속하는지 계산합니다. 또한 Region proposal의 좌표를 보정해주는 BBox Regression도 예측합니다.
아래쪽은 각 픽셀마다 객체인지 아닌지 확인합니다.