[cs231n] 9강 리뷰
CNN Architectures AlexNet, VGG, GoogleNet, ResNet etc.
contents

Main
- Lenet
- AlexNet
- VGG
- GoogleNet
- ResNet
Sub
- NiN (Network in Network)
- Wide ResNet
- ResNeXT
- Stochastic Depth
- DenseNet
- FractalNet
- SqueezeNet
LeNet
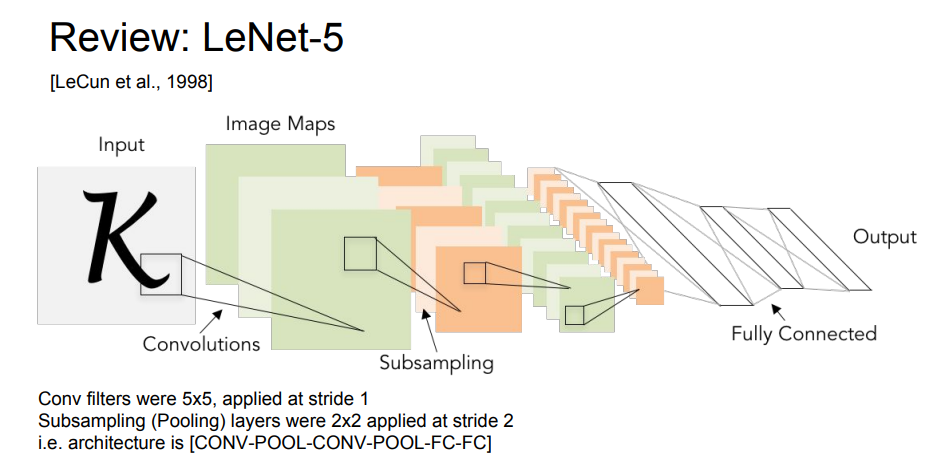
처음으로 볼 구조는 1998년에 나온 모델 LeNet입니다.
CONV-POOL-CONV-POOL-FC-FC
매우 간단한 구조를 가졌습니다.
직관적으로 이해하기도 쉽습니다.
AlexNet
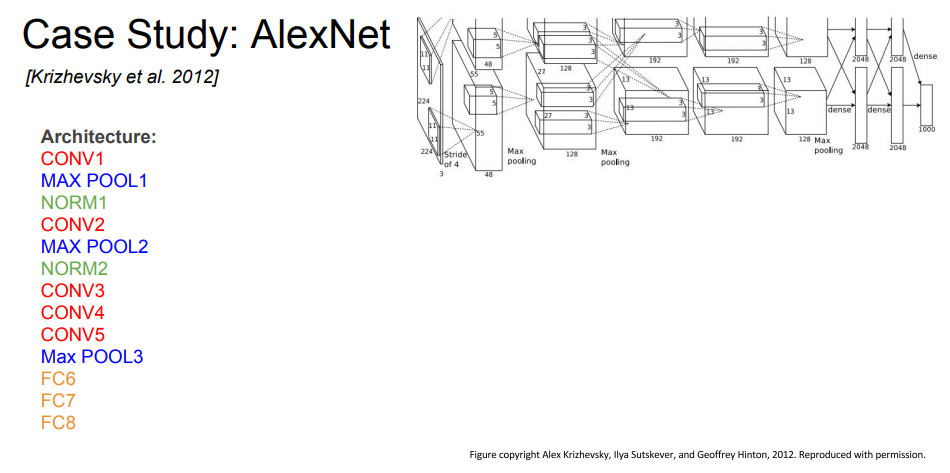
두 번째로 볼 모델은 2012년에 나온 AlexNet입니다.
가장 큰 특징은 처음으로 큰 규모의 CNN을 적용했다는 점입니다.(또한 Image Classification task도 잘 수행했습니다.)
Architecture
구조는 CONV-POOL-NORM이 두번 반복되는 형태입니다.
5개의 CONV layer, 3개의 POOL layer, 3개 FC layer와 Norm layer가 있지만 LeNet과 크게 다르지 않습니다. 다만 더 깊어진 것이죠.
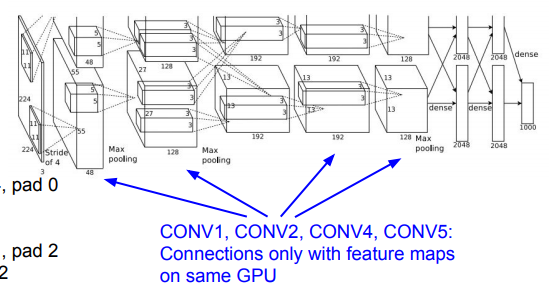
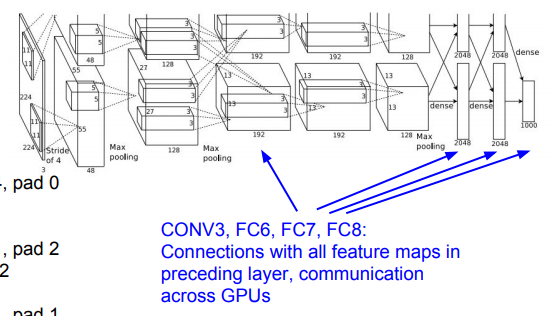
추가적으로 차이점은 GPU 2개를 병렬적으로 사용했다는 것입니다. 이 때 당시의 GPU 메모리가 크지 않았기 때문에 2개를 한번에 사용했습니다.(입력후에 위 아래로 두개의 층을 확인할 수 있습니다. 또한 FC layer에서는 서로 정보를 주고 받습니다)
파라미터 수
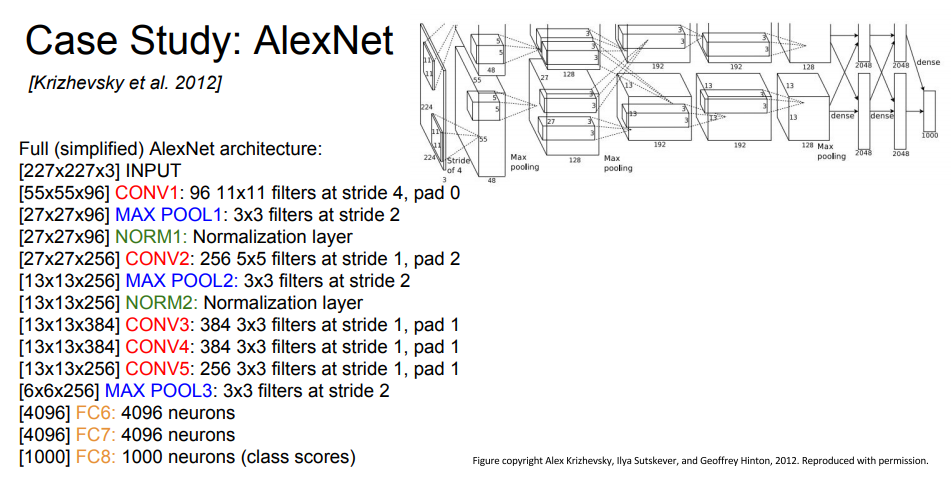
1 layer
input data = (227 _ 227 _ 3) _ 그림에는 224인데 227의 오타
filter = (11 _ 11 * 3) & filter 96개
Stride = 4
Output size = (N - F)/stride + 1 => (227 - 11)/4 + 1 = 55
Output Volume = [55 * 55 * 96] Parameter = (11 x 11 x 3) x 96 =35K
Note: 당시 메모리 용량이 3G밖에 안돼서 filter를 48개씩 데이터를 반으로 나눠서 넣었기 때문에 (555548) x 2개
Tip: 파라미터의 개수 : (업데이트해나갈 값, 가중치같은것) (11 _ 11 _ 3) _ 96 _ 모든필터안의 총 가중치 개수
2 layer
Input: 227x227x3 images
After CONV1: 55x55x96
Second layer (POOL1): 3x3 filters applied at stride 2
Output volume: 27x27x96 * (55-3)/2+1 = 27
Parameter= 0!
Note: Pooling layer는 필터 안의 데이터 값 중 특정값(Average, Max 등)을 골라서 데이터사이즈만 변환시키기 때문에 가중치가 없다.
특징
-
비선형함수로 ReLU를 사용
-
regularization
① Data augmentation(regularization의 일환으로 train data에 변형을 주는 것)을 많이 했다.
: flipping, jittering, clipping, color normalization 모두 적용
② Dropout 0.5
- batch size 128
Batch Normalization
- 딥러닝에서는 수많은 hiden layer를 거치면서, 초기데이터의 분포가 변하게 된다.
- 학습데이터와 테스트데이터셋의 분포가 다르면 예측이 적절히 이루어지지 않듯이, 뉴럴네트워크에서도 layer마다 들어오는 데이터의 분포가 달라지게 되면 적절한 학습이 이루어지지 않는다.
- 이를 해결하기 위해 매층마다 데이터의 분포를 재조절해주는 Batch Normalization이 등장한다.
Batch란 전체 데이터를 세트를 나눠서 학습시킬때, 은닉층에 들어온 데이터세트를 말한다.
1. 정규화 : 배치데이터의 평균, 분산을 이용해 정규화
2. scale(범위조정), shift(이동) : scale을 위해 γ, shift에는 β값을 하이퍼파라미터로 사용하고, backpropagation을 통해 이 값들 또한 학습한다.
-
SGD Momentum 방식 Optimization
-
Learning rate 1e-2 에서 시작해 val accuracy가 더이상 올라가지 않는 학습지점부터 서서히 1e-10으로 내림
-
weight decay : L2 Weight decay
학습과정에서 과적합이 발생하며 모델의 복잡도가 너무 높아지면 학습데이터에 대한 loss값은 최소가 될 수 있지만, 실제 test data에서는 accuracy가 떨어진다. 특정 feature에 너무 큰 가중치가 업데이트 되지 않도록 loss function에 weight가 커질 경우에 대한 패널티를 부여하고, 주로 L1 또는 L2 regularization을 사용한다.
- ensemble 기법 사용
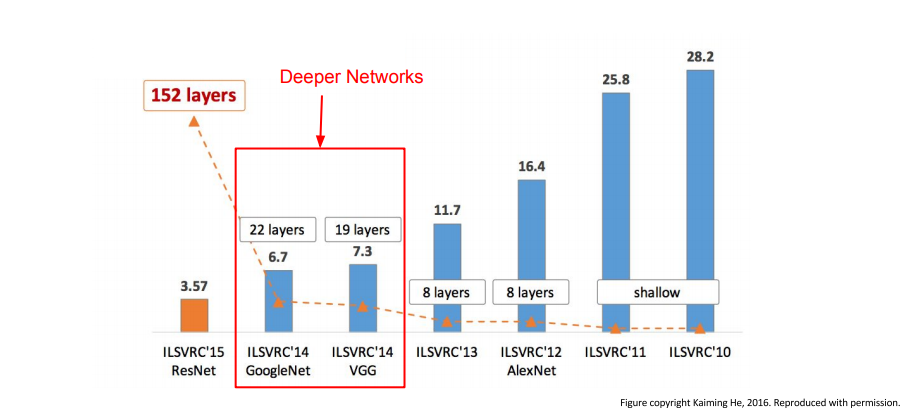
다음으로 볼 구조는 VGG와 GoogleNet입니다. 둘 다 2014년도에 나왔으면 나란히 VGG는 2등 GoogleNet이 1등을 거머줬습니다.
VGG
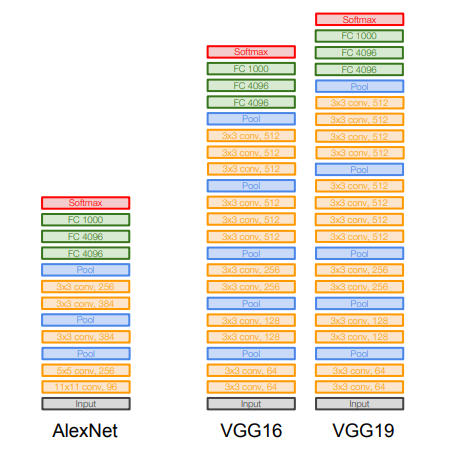
보시다시피 AlexNet과의 차이점은 더 깊어진 것이라고 볼 수 있습니다. 하지만 추가적으로 작은 필터값을 사용했다는 차이점이 있습니다
8 layers (AlexNet)
-> 16 - 19 layers (VGG16Net)
오직 3x3 CONV stride 1, pad 1 and 2x2 MAX POOL stride 2
11.7% top 5 error in ILSVRC’13(ZFNet)
-> 7.3% top 5 error in ILSVRC’14

마찬가지로 이미지에서 receptive field란 필터가 한 번의 보는 영영으로 볼 수 있는데, 결국 필터를 통해 어떤 사진의 전체적인 특징을 잡아내기 위해서는 receptive field는 높으면 높을 수록 좋다. 그렇다고 필터의 크기를 크게하면 연산의 양이 크게 늘어나고, 오버피팅의 우려가있다. 그래서 일반적인 CNN에서는 이를 conv-pooling의 결합으로 해결한다. pooling을 통해 dimension을 줄이고 다시 작은 크기의 filter로 conv를 하면, 전체적인 특징을 잡아낼 수 있다. 하지만 pooling을 수행하면 기존 정보의 손실이 일어난다. 이를 해결하기 위한것이 Dilated Convolution으로 Pooling을 수행하지 않고도 receptive field의 크기를 크게 가져갈 수 있기 때문에 spatial dimension의 손실이 적고, 대부분의 weight가 0이기 때문에 연산의 효율도 좋다. 공간적 특징을 유지하는 특성 때문에 Dilated Convolution은 특히 Segmentation에 많이 사용된다.

->layer를 더 깊게하고 파라미터 수를 줄여 효율성을 깊게 만들기 위해서였습니다
3x3 conv (stride 1) layer를 3개 쌓으면 7x7 conv (stride 1)과 같은 수용영역(Receptive field)를 갖는다고 합니다. 즉, filter size가 똑같은데 3x3을 쓰면 더 깊게 쌓을 수 있는 것이죠
파라미터 수를 계산해보면,
3x[3x3(필터의 가중치 수)xC(채널의 수)]이므로 3^3XC가 됩니다.
7^2 x C > 3^3 x C 이므로, 파라미터의 수가 훨씬 적죠.
그래서 3x3의 필터를 고집한 것입니다.
여기 보면 total 메모리가 only forward 과정에서만, image 1개당 거의 100mb가 필요합니다.
전체 메모리가 5GB라면, 50장밖에 못하는 거죠…
알렉스 넷은 60MB가 필요했는데, layer가 깊어진 만큼 메모리 부담이 크게 늘어납니다.
강의 내 Q&A 입니다.
Q : 쓸모없는 것들도 많은 텐데 꼭 memory를 많이 써가면서 연산을 전부 저장해야하는가?
A : 전부는 아니지만, NN은 Backward에서 체인룰을 이용해서 update해나가기 때문에 상당 부분의 연산을 저장 해야한다.
GoogleNet
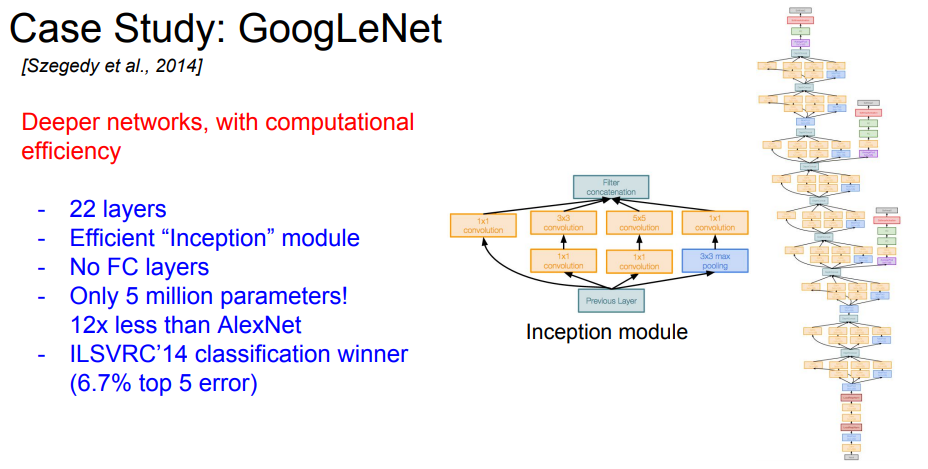
3번째 main GoogleNet입니다.
- 22 layer
- Inception module
- 파라미터 개수를 줄이기 위해 FC layer가 없음
- 파라미터가 너무 많았던 AlexNet에 비해 5M개 밖에 없다
- 2014년도 우승 모델
사실 inception module이란 개념을 처음 접해서 어..? 이걸 왜쓰지? 이게 뭐지.. 하면서 잘 이해가안됐던 부분이였습니다. 하지만 강의를 들으면서 상당히 fancy한 구조라는 걸 알게되었습니다.
Inception Module
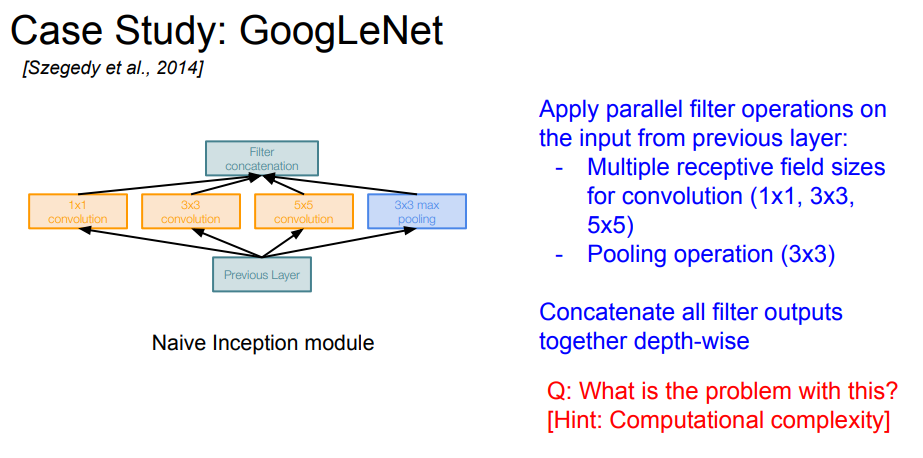
간단하게 Naive한 구조를 살펴보면 이전 레이어의 값들을 CONV와 POOL layer에 나눠줍니다.(병렬계산)
그리고 결과값들을 concatenation layer에서 합쳐주는 작업을 반복합니다.
Point 1
각 필터에 stride는 무조건 1로하고, 3x3, 5x5에 각각 제로패딩을 해주어서 size가 같은 feature map들이 나오게해서 concate 시켜줍니다.
그렇게 하면, 위 슬라이드를 예로 각각의 filter로 부터 전부 같은 size의 feature map들이 나오게 되는데, 이는 기존의 한 layer에서는 무조건 같은 사이즈의 filter만 썼던 것과는 달리 굉장히 다양한 특성을 지닌 feature map들을 얻을 수 있습니다. (concate를 하면, 4개의 필터를 거친 같은 사이즈들의 feature map들을 묶는 것입니다.)
Point 2
굳이 1x1 filter를 쓰는 이유는 각각 필터값들이 변하지 않은 채로 depth가 줄어듭니다.
가령, 28x28x128의 feature map을 1x1x128필터를 16개쓰면 28x28x16개로 depth를 줄여서 연산량을 많이 줄일 수 있죠.
Point 3
3x3 Pooling 했을 때, max Poolig을 해주면 이전 stride의 max값이 다음 stride의 필터에도 겹쳐서 좋은 값을 여러번 쓸 수 있습니다.
이미지 내에서 특징이 강한 픽셀값을 여러번 쓸 수 있는 것입니다.
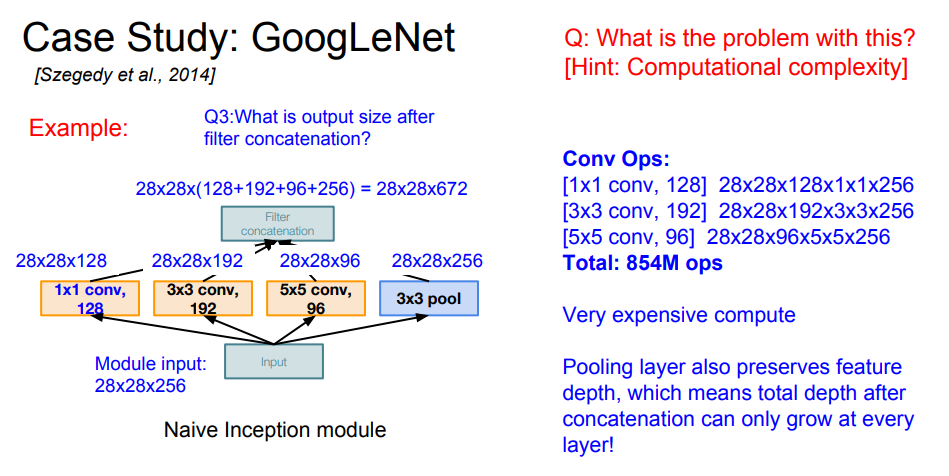
하지만 위와 같이 Navie한 구조는 연산량이 기하급수적으로 증가하는 문제가 있습니다. 같은 size의 feature map들을 concate해주면, 128+192+96+256 = 672개 channel이므로 854M의 연산을 통해서 28x28x672 feature map이 나옵니다.Inception module하나에서 854M ops인데 다음 모듈로 넘어갈 때마다 depth가 꾸준히 증가하기 때문에 연산량도 함께 증가하게 될 것입니다. 또한 Pooling layer에서 depth를 줄이지 못한다는 문제도 있습니다.
**Bottleneck Architecture**그래서 Bottleneck Architecture를 사용하여 해당 문제를 해결합니다.
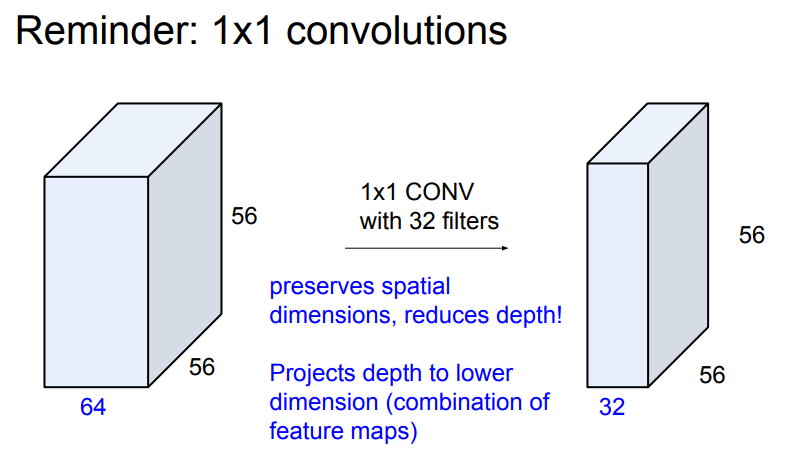
간단하게 1x1 conv를 통해서 채널의 개수를 줄여줍니다
**Inception Module**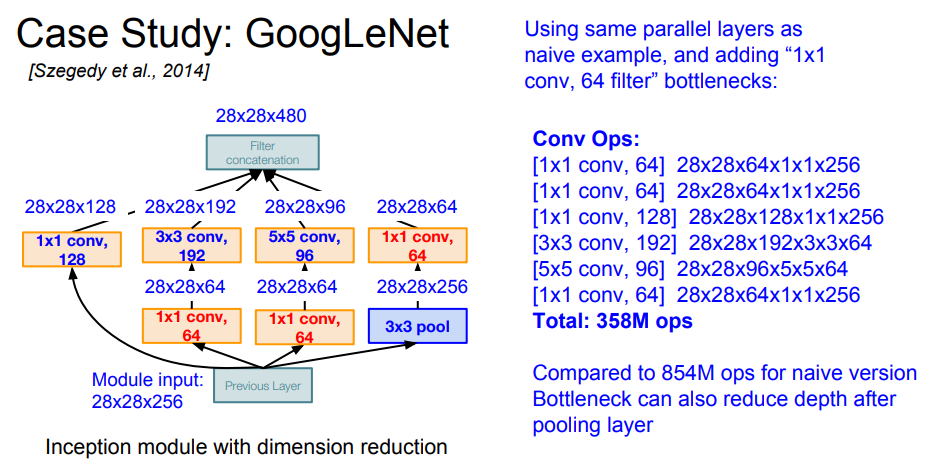
- inception module 안에 bottle neck layer를 추가해보면 합성곱계산량이 358M개로 줄어드는 것을 볼 수 있다.
- pooling layer의 경우 depth를 줄이기 위해 이후에 1x1 conv layer를 깔게 되는데, 이를 통해 depth도 줄여 4개의 output을 모두 concatenate한 depth 또한 줄일 수 있다.
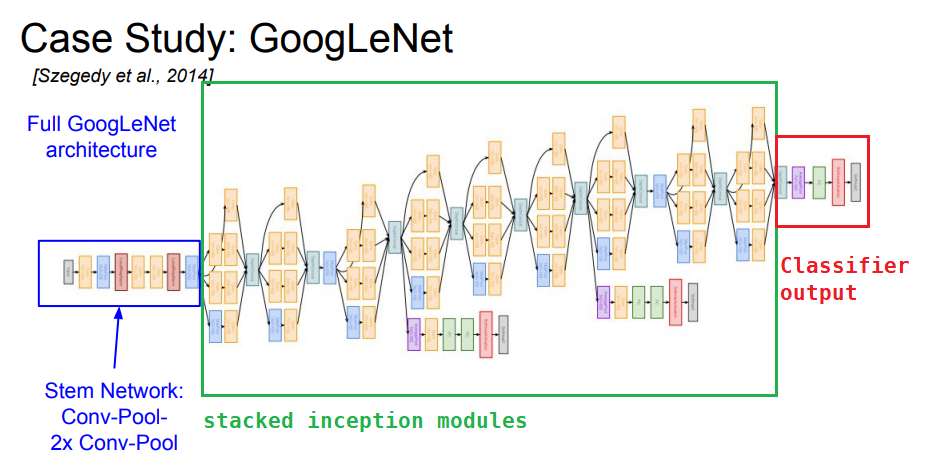
-
Stem Network
- 일반적인 네트워크 구조로 시작한다.
Conv-Pool-Conv-Conv-Pool
- 일반적인 네트워크 구조로 시작한다.
-
Inception Modules 이 쌓이는 중간층
-
Classifier output
-
특히 FC layer를 없애서 parameter를 확 줄였는데, 그래도 잘 돌아갔다고 한다.
-
FC layer 대신 global average pooling layer(보라색 노드)을 깔았는데, 기존 FC layer는 feature map을 1차원벡터로 펼쳐서 Relu와 같은 활성화함수를 거친뒤 Softmax로 분류하게 되었는데, Global Average Pooling은 직전층에서 산출된 feature map 각각 (그림에서는 depth방향으로 1024개) 평균내는 방식의 Pooling layer라고 생각하면 된다.
-
1차원 벡터로 만들어야 softmax를 사용할 수 있고, FC layer로 활성함수를 거치지 않아도 이미 깊은 네트워크를 거치면서 효과적으로 Feature vector를 추출했기 때문에, 이정도만해도 분류가 가능했다고 한다.
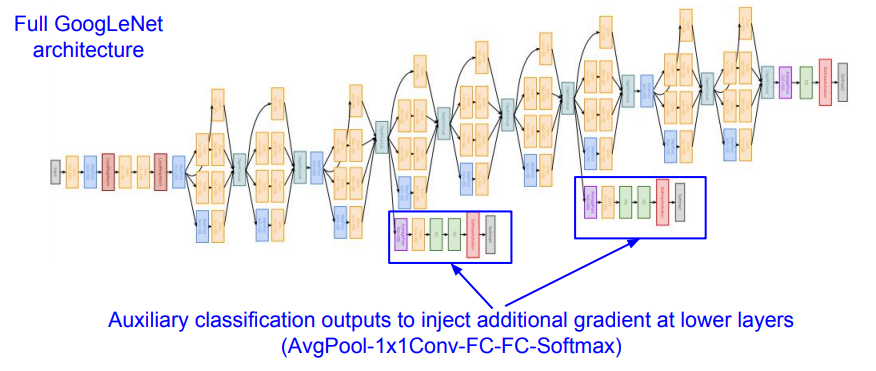
- Auxiliary classification
- 네트워크가 깊다보니 back propagation을 할 때 gradient vanishing문제가 발생하기가 상대적으로 더 쉽다. 그래서 중간 정류장에서 gradient와 loss까지 계산해놓고, back propagation시에 도와준다.
- 훈련시에만 달아준다.
Resnet
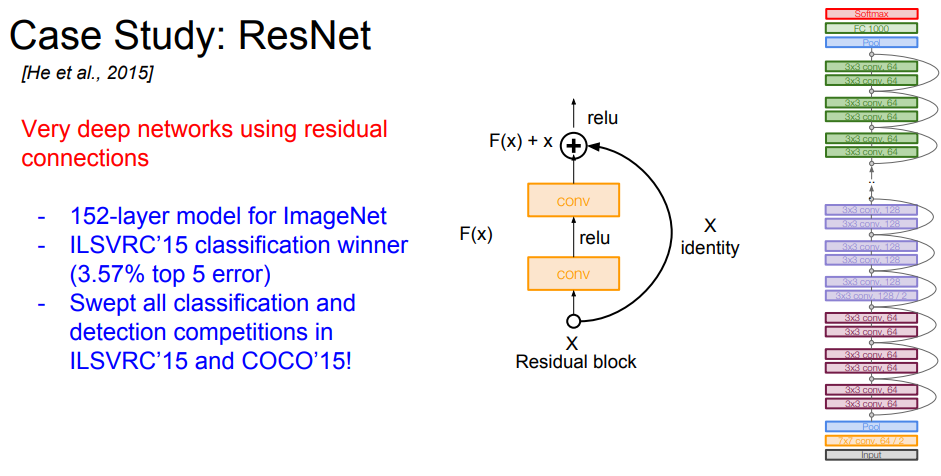
ResNet은 Residual block이라는 방법을 사용합니다
- ImageNet을 위한 152 layer 모델
- ILSVRC’15 분류 1등(3.57% top 5 error)
- also COCO classification/detection 대회 우승
Basic motivation
일반 CNN을 깊고 더 깊게 마들면 어떻게 될까?
레이어만 깊게 쌓으면 성능이 좋아질까?
Answer: No

[우측] test error에서 보면 깊은 레이어가 오히려 더 안좋다
[좌측] training error를 보면 56-layer가 많은 파라미터가 있으니 overfit되어 error가 낮아야 할 것 같지만 정반대의 결과가 나왔습니다.
따라서 test 성능이 낮은 이유가 over-fitting때문만은 아닌것을 알 수 있습니다.
가설: 더 깊은 모델 학습 시 optimization문제가 생긴다.(overfit때문이 아니라)
추론: “모델이 더 깊으면 얕은 모델만큼은 성능이 나와야 하지 않을까?”
예시: 더 얕은 모델의 가중치를 깊은 모델의 일부 레이어에 복사
-> 그리고 나머지 레이어는 identity mapping을 하는것
-> 깊은 모델은 적어도 얕은 모델만큼의 성능이 보장됩니다.
identity mapping: input을 output으로 그대로 내보냄
Model Architecture

기존에는 왼쪽의 그림 처럼 H(x)를 학습했습니다.
- Residual block
input: 이전 레이어의 output
target: F(x)
output: F(x)
+x+x를 Skip connection(or Shortcut connection)이라고 부르며 가중치가 없으면 입력을 identity mapping으로 그대로 출력으로 보냅니다.
이렇게되면 실제 레이어는 변화량(delta)만 학습하면 됩니다.
이 변화량은 입력 X에 대한 잔차(residual)이라고 할 수 있습니다.
저는 맨처음 식을 볼때 F(x)가 H(x)-x인데 output이그럼 결국 H(x)를 학습하는거 아니냐는 바보같은 생각을 했습니다.
사실은 이게 아니라 F(x)를 학습하고 나서 x를 더해주는 것입니다.
정리
제가 이해한대로 풀어보자면 기존의 학습 방법은 H(x)를 학습하는데 많은 리소스가 들었습니다.
하지만 residual block은 잔차만 학습한다고 했는데 그 이유는 F(x)를 학습하고 output으로 내보낼 때 input을 한 번 추가해줍니다.
이렇게 되면 F(x)는 함수 F()를 통해 변환된 x의 값 즉 변화된 값이 됩니다.
output을 보면 F(x)+x입니다. x를 입력해서 나온 값이 x+x의변화량입니다.
저희는 이 input과 output의 잔차(Residual) F(x)을 학습합니다.
다시말해 이전 레이어의 X값을 보존하고 추가적으로 필요한 정보를 학습하는 방식으로 진행됩니다.
그렇지 않고 매번 새로운 학습을 하는 경우보다 학습하기 쉽다.
극단적으로 Input=Output optimal이라는 상황입니다.
그럼 레이어의 출력인 F(x)가 0이어야 하므로(residual=0) F가 0이 되도록 학습하는게 난이도가 더 낮습니다.
차원이 다를 경우
Input차원과 output차원이 다를 경우 linear projection Ws를 x에 곱해줌으로써 차원을 맞춰줍니다.(또는 Zero-padding 사용)
하지만 F가 single layer라면 이건 단지 linear layer이기 때문에 아무런 성과가 없습니다.

- 기본적으로 하나의 Residual block은 두 개의 3x3 conv layers로 이루어짐
- 주기적으로 필터를 두배로 늘리고 stride 2 Downsampling
- No FC layer, instead GAP layer(하나의 Map 전체를 Average Pooling)
- 마지막에 1000개의 클래스 분류용 노드

Depth가 50 이상일 때 Bottleneck Layers를 사용(GoogLeNet과 유사함) 1x1 conv 초기 필터 depth 줄이고 마지막에 한 번 더 사용해서 depth를 줄임