[cs231n] 8강 리뷰
하드웨어와 딥러닝 프레임워크

- 본 포스트는 cs231n 8강 리뷰입니다.
CPU vs GPU
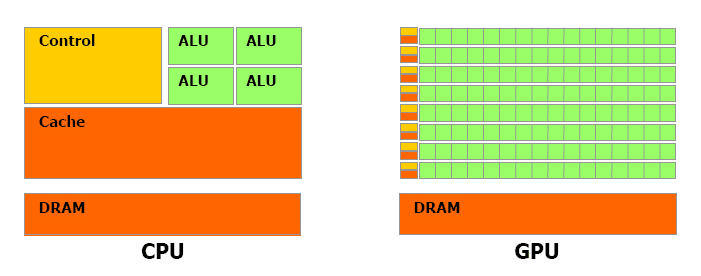
- CPU(central processing unit)
- GPU(graphics processing unit) <- 게임을 위해서 만들어졌다.
NVIDA vs AMD
딥러닝의 경우는 NVIDA
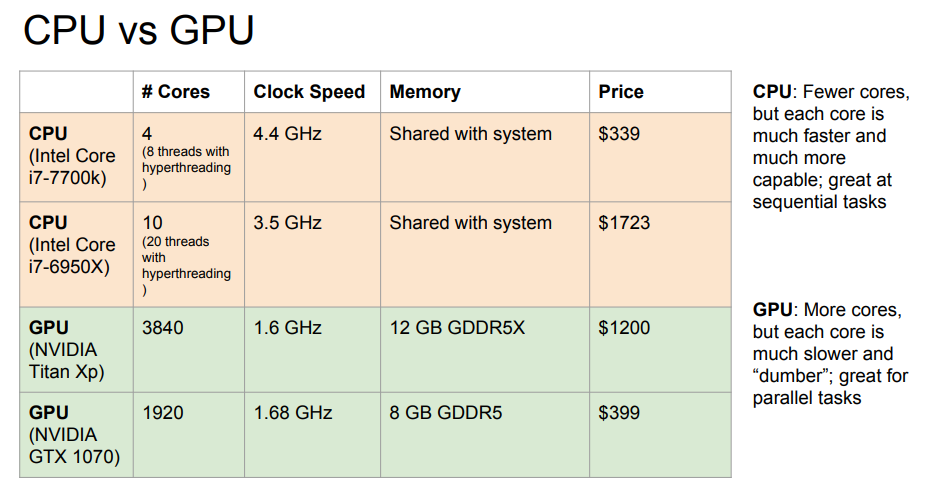
두개의 차이 (표CPUvsGPU)
둘다 임의의 명령어를 수행하는 범용 컴퓨터 머신
CPU는 코어 수가 적다 8~20개의 쓰레드를 동시 실행가능하다
독립적으로 아주 많은 일을 할 수 있고 빠르다
GPU는 수천개의 코어가 있다 단점
- 각각의 코어가 더 느린 clock speed에서 동작한다
- 그 코어들이 그렇게 많은 일을 할 수 없다
많은 코어들이 하나의 테스크를 병렬적으로 수행한다
병렬로 수행하기 아주 적합하고 같은 테스크여야 한다
사실 1:1로 두개를 비교하는것은 바람직하지 않다
코어수만 가지고 비교하기 어렵다
메모리
CPU에도 캐시가 있지만 작다 대부분 메모리를 RAM에서 끌어다 쓴다(보통 8, 12, 16, 32GB 정도)
하지만 GPU에는 RAM이 내장되어 있습니다. 실제 RAM과 GPU간의 통신은 상당한 병목현상을 초래합니다. 그래서 보통 RAM이 내장되어있습니다
GPU코어 사이의 캐싱을 위한 일종의 다계층 캐싱 시스템을 갖고 있습니다.(CPU의것과 유사함)
CPU는 범용처리
GPU는 병렬처리에 적합하다
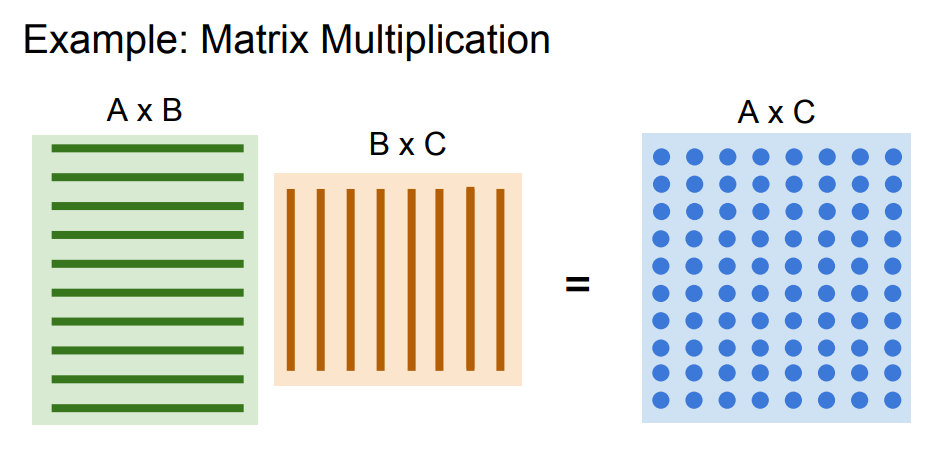
GPU에서 정말 잘하는 알고리즘중 하나는 Matrix Multiplication
파란색 행렬은 왼쪽 두 행렬의 내적입니다. 이 때의 내적 연산은 모두 서로 독립적입니다.
각각의 원소가 전부 독립적이므로 모두 병렬로 수행될 수 있습니다
Conv또한 입력과 가중치간의 내적을 구하는 것이기 때문에 GPU에서 빠르게 연산이 가능하다
Programing GPUs
-
CUDA(NVIDA only)
- CUDA 코드를 직접 작성하기는 매우 어렵기 때문에 NVIDA에서 딥러닝을 위한 GPU를 위해 고도로 최적화시킨 기본연산 라이브러리를 배포해 왔습니다
-
GPU에서 아주 잘 작동하고 하드웨어 사용의 이론적 최대치까지 끌어올려 놓은 라이브러리입니다
- cuBLAS(다양한 기본연산), cuFFT, cuDNN(Conv,fw,bw pass, bn, rnn, etc), etc
-
OpenCL
- 좀 더 범용적이며 CUDA와 비슷하다.
- NVIDA GPU, AMD, CPU에서도 동작한다.
- 아직 극도로 최적화된 연산이나 라이브러리가 개발되지 않았다. CUDA보단 성능이 떨어짐.
cuDNN 꼭 쓰자 제발
모델은 GPU RAM에 있지만 Training set은 SSD, HDD에 있다
로딩작업을 신경쓰지않으면 병목현상이 발생할 수 있다(GPU 연산은 빠르게 진행되는데 데이터 로드가 늦는경우)
Sol: 데이터셋이 작으면 전체를 RAM에 올려둔다, SSD를 사용한다.
- CPU의 다중스레드를 이용하여 RAM에 미리 올려놓는다(pre-fetching).
- buffer에서 GPU로 넘기면 성능향상 할 수 있다.
외전 TPU NPU 그들은 누구인가?
-
CPU(Centralized Processing Unit)
폰 노이만 아키텍쳐라고도 불리며 맨하탄 프로젝트 당시 제안되었던 전자계산기의 기본 구조를 따라 발전했다. -
GPU(Graphic Processing Unit)
초기에는 그래픽 처리에 필요한 대용량 연산을 위한 Co-processor형태로 출발
CPU는 순차처리 방식이기 때문에 많은 연산을 한꺼번에 할 수가 없고 느리다.
ex)가령 FPS게임을 할려면 픽셀 렌더링도 해야하고 텍스쳐 연사도해야하고 엄청 많은 연산을 하게 되는데 이것들을 CPU로 하면 얼마나 느릴까 GPU가 없는 컴퓨터로 게임을 하면서 얼마나 답답했는지 느껴보시면 GPU가 얼마나 좋은 친구인가 알 수 있습니다. -
TPU(Tensor Processing Unit), NPU(Neural Processing Unit) NPU는 GPU에 신경망에서 처리해야 하는 곱셈 연산을 나눠서 시키는 불편함과 리소스 cost를 줄이고 Neural Network Processing에 특화된 칩셋을 말합니다.
TPU는 구글에서 제작한 NPU의 이름입니다. TPU가 탑재된 Coral 시스템도 NVIDA또는 NPU와 하는일이 크게 다르지 않으며 Tensorflow lite가 조금 더 잘 호환된다는 등 제작사의 요구사항이 반영되어 있는 NPU라는건데.. 결국 구글이 Tensorflow를 갖고 있으니 특화된 서비스를 내놓은 것 같은 느낌 출처:https://voidint.com/2020/10/14/cpu-gpu-tpu-npu/
딥러닝 프레임워크
초기 딥러닝 프레임워크는 학계에서 많이 사용되었지만 다음 세대는 산업에서 태동이 일어났다.
- Caffe(Berkeley), Torch(NYU, Facebook), Theana(Montreal)
- PyTorch(Facebook), TensorFlow(Google)
딥러닝 프레임워크를 이용하는 3가지 이유
- 쉽게 엄청 복잡한 그래프를 직접만들지 않아도 된다
- gradients 자동으로 계산된다(forward pass만 잘 해놓으면 back prop는 자동 구성)
- GPU에서 효율적으로 사용할 수 있다(밑바닥 부터 구현하지 않아도 됨)
Numpy vs TensorFlow vs PyTorch
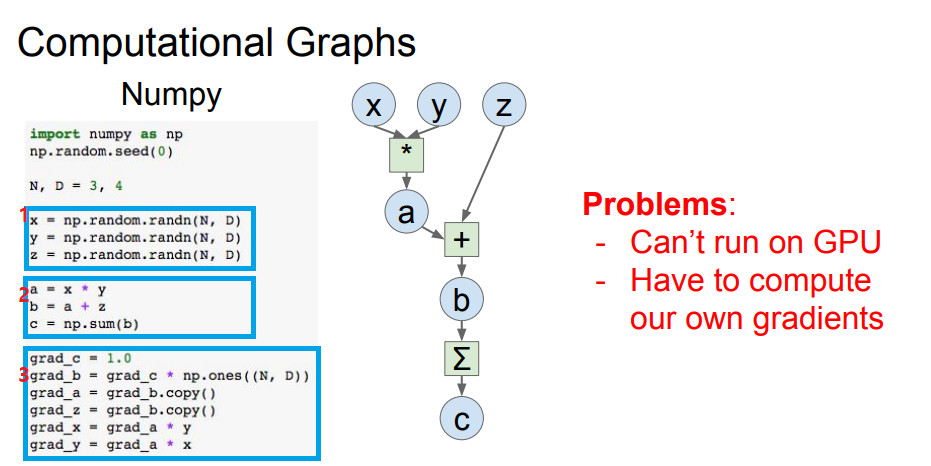
- 랜덤으로 x,y,z를 할당
- 계산
(1,2번은 Forward pass를 구축) - gradients 구하기
문제점
GPU를 사용하지 못하고(Numpy는 CPU만 사용가능;;)
gradients를 직접 계산해야함
 위쪽 빨간색 박스는 tensor의 placeholder를 x,y,z로 만들어주고 식을 만들고
위쪽 빨간색 박스는 tensor의 placeholder를 x,y,z로 만들어주고 식을 만들고
아래쪽 박스는 tf내장함수로 gradients를 구하는 식을 작성한다
 빨간색 박스로 되어있는 곳에 cpu 또는 gpu라고 작성하면 해당하는 unit으로 연산할 수 있다.
빨간색 박스로 되어있는 곳에 cpu 또는 gpu라고 작성하면 해당하는 unit으로 연산할 수 있다.

- Numpy로 back propagation까지 하기는 뭔가 좀 귀찮음을 느낄 수 있다.
- TensorFlow는 특이하게 with tf.Sesstion() as sess: 구문을 시작으로 나뉠 수 있다.
위쪽은 식을 정렬하고 아래는 식을 실행하는 부분이다 - PyTorch식은 다른 두개에 비해 더 간단해 보인다. c.backward()로 연산을 수행한다.