[cs231n] 5강 리뷰
Convolutional Neural Networks

Tip: 이미지를 클릭하시면 바로 유튜브 강의를 볼 수 있습니다.
- 본 포스트는 cs231n 5강 리뷰입니다.
5강 CNN(Convolutional Neural Networks)
CNN’s history
현대화가 시작된 것은 2012년 Alex Krizhevsky가 발표한 AlexNet 이후입니다.
기존의 NN보다 더 크고 깊어진 NN입니다. 가장 중요한 점은 대규모의 데이터를 활용할 수 있다는 점과 GPU를 사용할 수 있다.
CNN은 어디에 쓰는가?
- Search
- Recognition(Image, Pose, and etc)
- Detection
- Segmentation
- 자율주행 등
- 게임(Altari)
- Medical dignosis
- Astrophysics
- Captioning
CNN Architecture
Fully Connected Layer
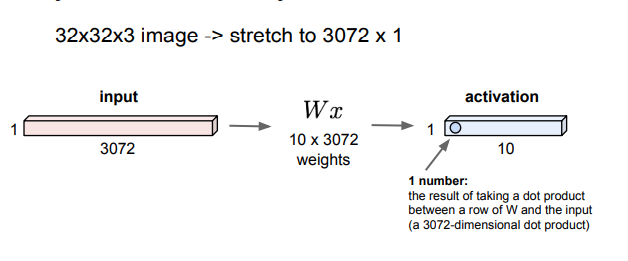
- image 32X32X3 -> 3072X1 형태로 바꿔준후에 input에 넣는다
- 가중치 W와 input 벡터를 곱해준다(=Wx)
- Activation을 통해 output(layer의 출력)를 얻는다.
Convolution Layer
FC레이어와의 큰 차이점은 Convolution layer는 기존의 구조를 보존시킨다는 점입니다. FC레이어에서 입력이미지를 곱을 통해 일자로 쭉 펴줬다면 Convolution layer는 기존의 이미지 구조를 그대로 유지합니다.
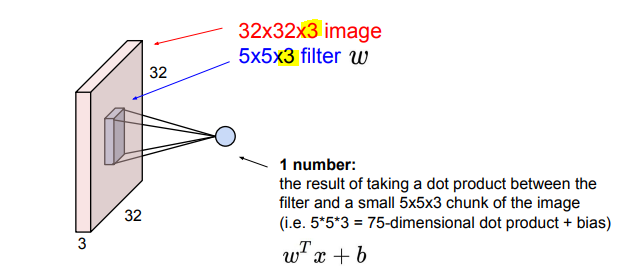
필터(filter) 가 우리가 가진 가중치W가 되는 것이고 이미지를 슬라이딩(말 그대로 슬라이드하듯 움직이면서)하면서 공간적으로 내적(dot products)을 수행하게 됩니다.
(사실 이해하기 쉽도록 슬라이딩 하듯이 움직인다고 했지만 실제로는 필터를 1X75로 펴서 벡터간 내적을 구합니다)
우선 필터는 입력의 깊이(Depth)만큼 확장됩니다. 그리고 필터의 크기만큼의 각 w와 겹쳐지는 input 이미지의 픽셀을 곱해줍니다.
필터는 이미지의 좌상단부터 시작하고 필터의 중앙에 값들을 모으게됩니다.왜냐하면 필터의 모든 요소를 갖고 내적을 수행하게 되면 하나의 값을 얻게 됩니다.
conv연산을 수행하여 나온 값들을 activation map이라는 출력값을 얻게 되고 maps의 해당하는 위치에 값들을 저장하게 됩니다. 출력 행렬의 크기는 슬라이드를 어떻게 하느냐에 따라 다르며 기본적으로는 하나씩 연산을 수행합니다.
보통 Convolution Layer에서는 여러 개의 필터를 사용합니다. 왜냐하면 필터당 하나의 특징을 얻을 수 있기 때문에 다양한 특징을 얻기 위해서는 여러 개의 필터가 필요합니다.
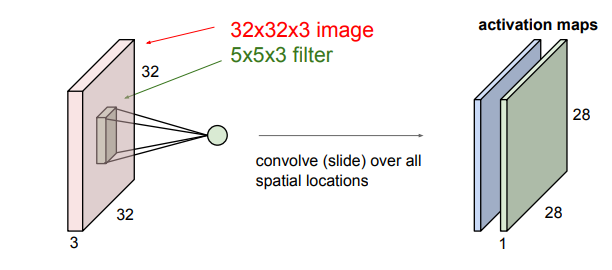
두 번째 필터는 녹색 필터입니다. 처음과 같이 이미지 픽셀에 conv연산을 해주고 나온 출력값들을 activation mpas에 저장합니다.
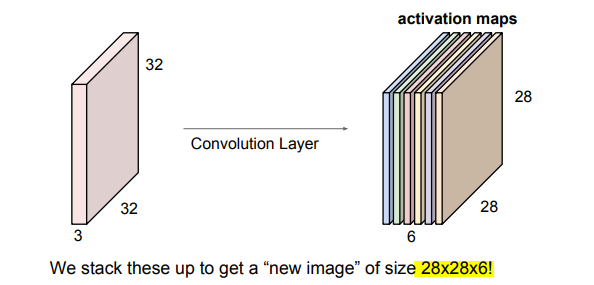
위와 같은 방법으로 우리는 5X5필터 6개로 총 6개의 activation map(28X28X6)를 얻게 되었습니다.
이 특징들을 뽑고나서 계층적으로 특징들을 조합해서 더 복잡한 특징으로 활용합니다. 예를들어 강아지의 사진이 있다고 했을 때 처음엔 귀쪽의 곡석 몸통의 직석과 곡선이라는 특징들을 뽑고서 이를 복잡하게 연결해가며 객체(강아지)에 가깝게 다가가는 것입니다.
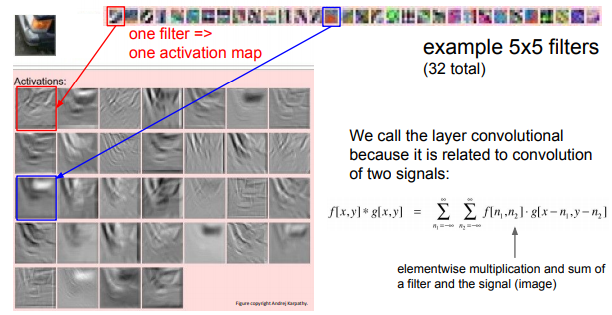
빨간색 테두리의 필터는 슬라이딩 하며 activation 값들을 출력하게 되는데 그 중에 빨간색 테두리 필터와 비슷할수록 더 큰 값들을 출력하게 됩니다.
우리가 이 과정을 Convolution이라고 칭하는 이유는 바로 위에 언급한 것이 바로 두 신호 사이의 convolution하는 것과 유사하기 때문입니다.

CNN의 일련의 과정을 보자면 Conv layer를 거치고 non-linear인 Relu 다시 Conv 후 Pooling layer를 거칩니다. Pooling은 activation map의 사이즈를 줄이는 역할을 합니다.
그리고 끝단에는 FC-layer가 있습니다 이를 통해 최종 스코어를 계산하게 됩니다.
Spatial dimension(공간적 구조)
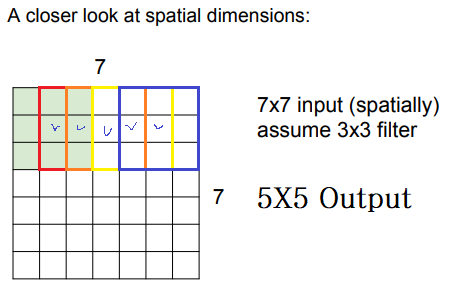
7x7 input, 3x3 filter가 있습니다.
filter는 input 위로 슬라이딩 하며 하나의 값들을 activation map에 저장할 텐데 파란색으로 체크된 부분만 값이 채워지면서 5x5 activation map을 만들게 됩니다.
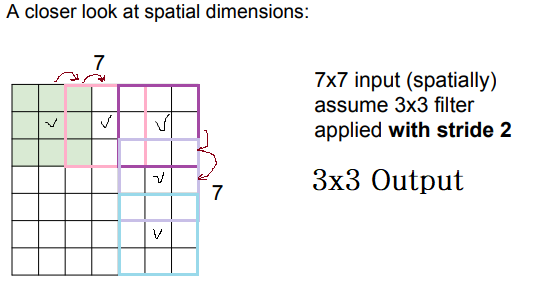
이번에는 stride를 2로 설정해보겠습니다.
위에서는 filter가 한 칸의 연산이 끝나면 바로 다음 칸으로 이동했지만 stride를 2로 설정하면 2칸씩 이동하게 됩니다.
그렇기 때문에 3x3 activation map이 출력됩니다.
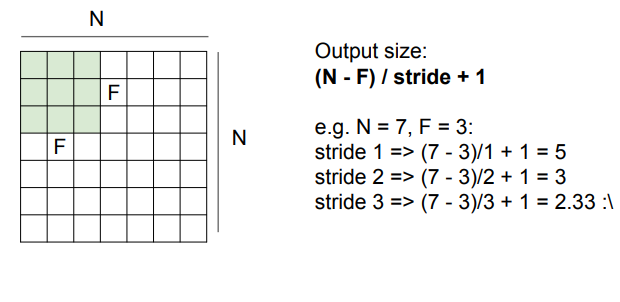
상황에 따라 출력 사이즈를 알 수 있는 수식이 있습니다.
어떤 stride를 사용했을때 이미지에 꼭 맞는지 그리고 몇 개의 출력값을 낼 수 있는지 알 수 있습니다.
-
stride를 크게 가질수록 출력은 점점 작아집니다.
Downsampling하는것과 Pooling은 비슷하지만 다르고, pooling보다 좋은 성능을 보이기도함 activation map의 사이즈를 줄이는 것은 추후 모델의 전체 params 개수에도 영향을 미칩니다
Zero Padding
제로 패딩이란 코너를 처리하는 방법으로 이미지의 가장자리에 0을 넣는 것입니다. 이 방법을 쓰는 이유는 레이어를 거치면서도 입력의 사이즈를 유지할 수 있습니다.(출력의 사이즈를 의도대로 만들 수 있다.)
-
사이즈를 유지하는 이유
만약 엄청 깊은 네트워크가 있다면 Activation Map은 레이어를 거치면서 점점 작아지게 될 것입니다.
= 일부 정보를 잃게되고 원본 이미지를 표현하기엔 너무 작은 값을 사용하게 될 것이다

왼쪽 표대로 output은 7x7x”필터의 개수(or =depth)”로 나오게 됩니다. 원래 공식에서 N=7이지만 0가 추가되어 9x9로 되었으니 N=9, F=3, stride=1을 사용해서 수식을 전개하면 됩니다.
basic fomula
(N-F/stride)+1
Zero padding fomula
(N+2*Zero-F)/Stride + 1
(9-3/1)+1 =7
이렇게 코너에 있는 정보를 처리하기 위해 Zero Padding을 사용했지만 반드시 Zero Padding만 사용해야하는 것은 아닙니다. 다른 방법으로 mirror, extend하는 방법도 있습니다
Exapmles
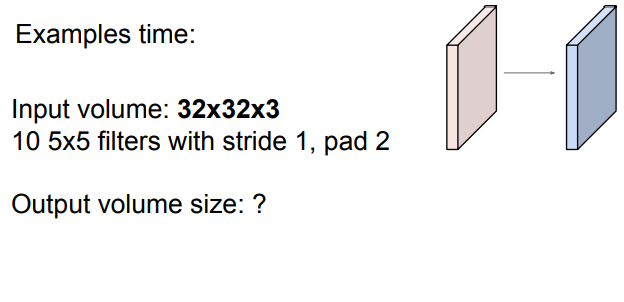
Zero padding fomula
*(N+2Zero-F)/Stride + 1**
위의 식을 이용해 봅시다
(32+2*2-5)/1+1
32x32x10(10인 이유는 10개의 filter라 명시함)
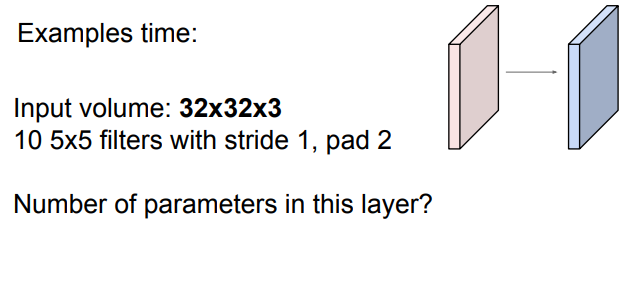
각각의 필터는 5x5x3+1=76 params(+1 for bias)
76x10=760 params
Summary

1x1 Conv layer(Bottleneck layer)
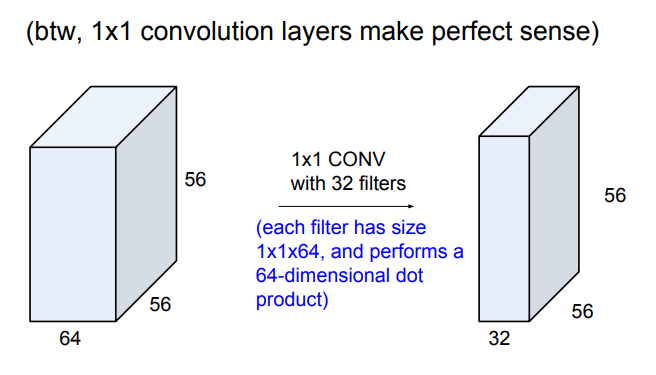 1x1 Conv도 의미가 있습니다 앞서 공부한 내용과 똑같이 슬라이딩하며 값을 구할 것입니다.
1x1 Conv도 의미가 있습니다 앞서 공부한 내용과 똑같이 슬라이딩하며 값을 구할 것입니다.
이 필터(1x1 Conv)는 입력의 전체 Depth에 대한 내적을 수행합니다
Bottleneck layer는 Depth를 줄이기 위한 테크닉중 하나입니다. 1x1 이상으로 해도 되지만 연산량이 증가하기 때문에 1x1이 적절합니다
Brain/Neuron view of Conv layer

뉴런의 관점에서 Conv layer를 살펴보겠습니다.
뉴런에서도 input과 Ws(filter)를 곱하고 하나의 값을 출력합니다.
하지만 큰 차이점은 뉴런은 Local connectivity를 갖고 있기 때문에 특정 부분에만 연결되어 있습니다.
하나의 뉴런은 한 부분만 처리하고 그런 뉴런들이 모여서 전체 이미지를 처리합니다. 이런식으로 activation map을 출력합니다.
- Activation map은 뉴런 출력값의 28x28 형태입니다.
- 각각은 작은 지역적 input과 연결되어있습니다.
- 모든 뉴런은 파라미터를 공유합니다.
한 뉴런의 Receptive filed는 5x5라고 할 수 있습니다. (Receptive filed는 하나의 뉴런이 한 번에 수용할 수 있는 영역)
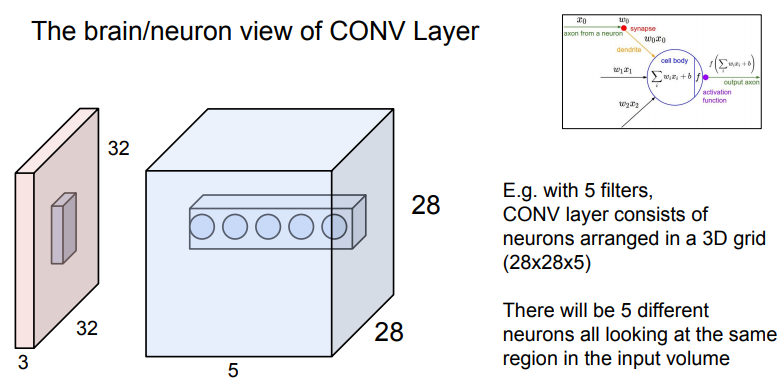 28x28x5의 3D activation map이 완성되었습니다.
28x28x5의 3D activation map이 완성되었습니다.
동그라미가 그려진 막대를 눈 앞에 둔다고 가정하면 각각의 값들은 input의 같은 지역에서 추출된 서로다른 특징이라고 할 수 있습니다.
Pooling layer
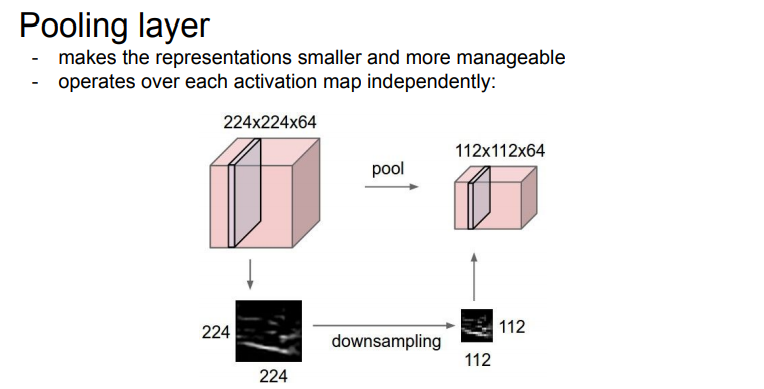 pooling layer는 공간을 줄여주고 더 관리하기 쉽게 만들어 줍니다.
pooling layer는 공간을 줄여주고 더 관리하기 쉽게 만들어 줍니다.
즉, Downsample하는 것입니다
여기서 중요한 점은 공간은 줄었지만 Depth는 그대로인 점입니다.
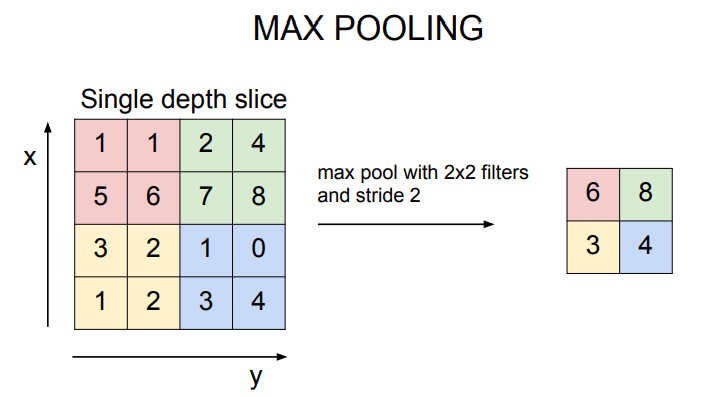 일반적으로는 Max pooling을 사용합니다.
일반적으로는 Max pooling을 사용합니다.
우리가 다루는 값들은 결국 얼마나 이 뉴런이 활성화되었는 지를 나타냅니다. Max pooing은 그 지역이 어디든, 어떤 신호에 대해 ‘얼마나’ 필터가 활성화 되었는지를 알려줍니다.
예를 들어, 얼굴 인식에서 눈에 해당하는 필터가 있습니다. 이 필터는 input된 얼굴을 슬라이딩 하며 activation map을 완성해 나갈 것입니다. 그 과정 중에 눈과 비슷한 곳을 슬라이드할 때 값이 얼마나 큰지가 중요합니다.
각각의 필터에서 가장 큰 값을 출력합니다
 또 다른 방법은 Average pooling입니다
각각의 값들을 더한 후 나눈 값을 출력합니다.
또 다른 방법은 Average pooling입니다
각각의 값들을 더한 후 나눈 값을 출력합니다.

pooling layer에서는 보통 padding을 사용하지 않습니다. 우리는 downsampling을 하고싶고 코너의 값을 계산하지 못하는 경우도 없기 때문입니다.
Fully Connected layer
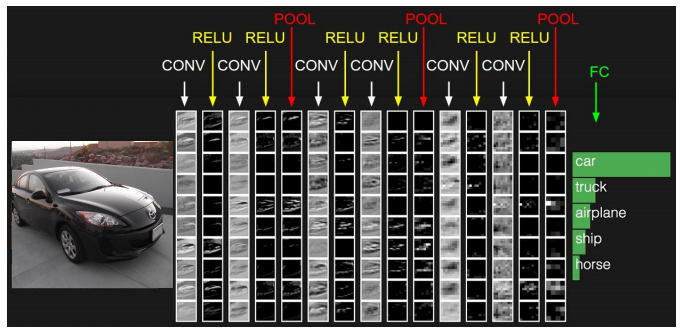 우리는 conv layer를 거쳐서 온 출력값(네트워크 집약체)들은 WxHxD로 이루어져 있습니다. 이것들은 1차원 벡터로 펴서 FC layer의 입력값으로 사용합니다.
우리는 conv layer를 거쳐서 온 출력값(네트워크 집약체)들은 WxHxD로 이루어져 있습니다. 이것들은 1차원 벡터로 펴서 FC layer의 입력값으로 사용합니다.