MLOps 기초: 1 주차
W&B
이제는 많은 분들이 알고 계신,,,
또 누구에게는 꽤 친숙한,,,
네. 1 주차는 **Weights and Bias(**W&B)입니다
사실 이번년도 상반기에 가짜 연구소에서 해커톤을 진행했었습니다. 그 때 우연히 참가하게 되어 Baseline을 설명해주시면서 이 모니터링 도구인 W&B를 설명해주셨었는데요. 한 두 번 쓰고 지속적으로 활용하지 못했던 것 같습니다. 이 기회를 통해서 좀 더 친해질려고 합니다.
Notice: 0주차의 transformer 모델을 잘 공부하고 오셔야합니다. 해당 모델을 개선하는 방향으로 시작됩니다.
실행환경: Colab

ML 모델 모니터링 모델을 모니터링 해야 하는 이유는 무엇인가요?
많은 이유가 있습니다. 예측의 정확성을 이해하고 예측 오류를 방지하며 모델을 조정하여 완벽하게 만들 수 있습니다.
일반적으로 하이퍼 파라미터를 조정하고, 성능을 테스트하기 위해 다른 모델을 시도하고, 모델과 입력 데이터 간의 연결을 확인하고, 고급 테스트를 수행하여 실험을 실행합니다.(엄청난 시간과 노력이 필요하겠죠..) 그런데 이 모든 것을 한 곳에 기록하면 더 빠르고 더 나은 통찰력을 얻는 데 도움이 됩니다.
모델이 원활하게 작동하는지 확인하는 가장 쉬운 방법은 ML 모델 모니터링 도구를 사용하는 것입니다.
또한 전용 도구를 사용하여 팀과 협업하고, 다른 사람들과 작업을 공유할 수 있습니다. 팀이 협업하고, 모델 생성 및 추가 모니터링에 참여할 수 있는 공유 공간입니다. 모델에서 발생하는 상황에 대한 실시간 통찰력이 있으면 아이디어, 생각 및 관찰을 교환하고 오류를 찾기가 더 쉽습니다. 기계 학습을 모니터링하는 데 사용할 수 있는 라이브러리가 많이 있습니다.
- Comet
- MLFlow
- Neptune
- TensorBoard
- Weights and Bias
- and many more
이 게시물에서는 다음 주제를 다룰 것입니다.
W&B로 기본 로깅을 구성하는 방법메트릭을 계산하고 W&B에 기록하는 방법W&B에 플롯을 추가하는 방법W&B에 데이터 샘플을 추가하는 방법
참고: 기계 학습, Pytorch Lightning에 대한 기본 지식이 필요합니다.
Weights and Bias Configuration
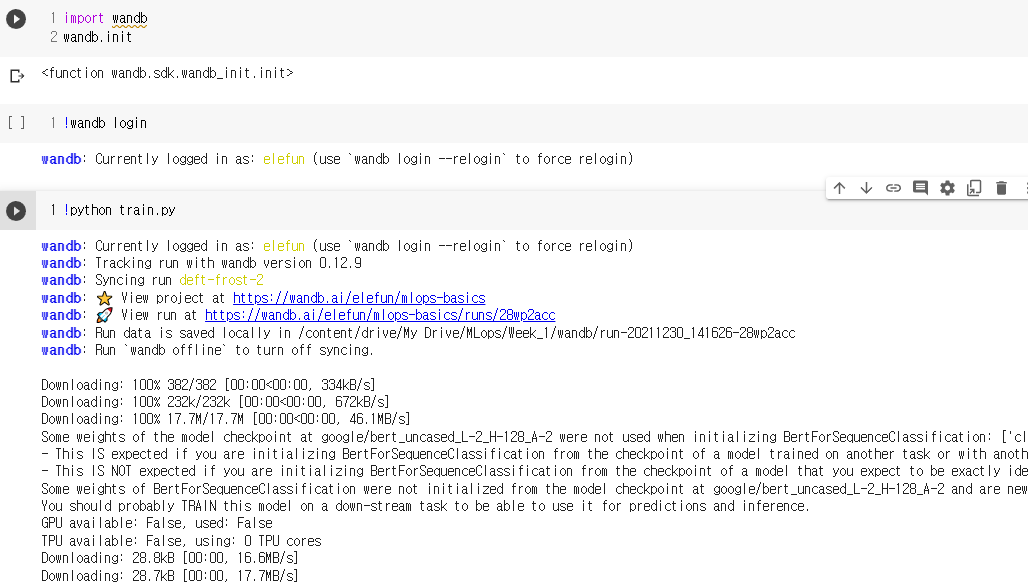
W&B를 이용하기 위해서는 계정을 생성해야 합니다. (공공 프로젝트 및 100GB 스토리지의 경우 무료). 계정이 생성되면 로그인해야 합니다
간편하게 Github을 통해 로그인했습니다.
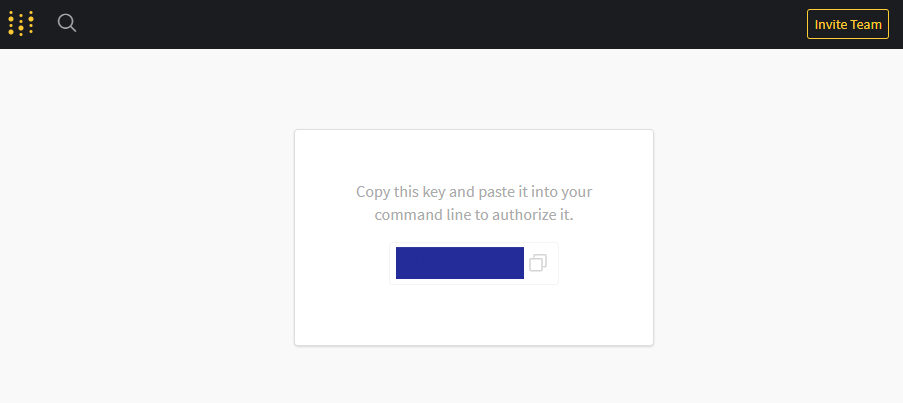
로그인 하게 되면 바로 인증을 위한 키를 받을 수 있습니다.

인증을 위한 키를 여기에 넣으시면 됩니다!
로그인이 잘 되었는지 궁금하시다면 다시 실행해 보세요. 잘 되었다면 아래와 같이 나옵니다.
wandb: Currently logged in as: elefun (use wandb login –relogin to force relogin)
📌Configuring
W&B에서 프로젝트를 생성하고 여기에 같은 이름을 사용하세요. 모든 실험이 해당 프로젝트에 로그인 되어 기록 되도록 합니다.
from pytorch_lightning.loggers import WandbLogger
wandb_logger = WandbLogger(project="MLOps Basics")
이제 logger를 Trainer로 전달합니다.
trainer = pl.Trainer(
max_epochs=3,
logger=wandb_logger,
callbacks=[checkpoint_callback],
)
이제 모든 로그는 W&B에 기록될 것입니다.
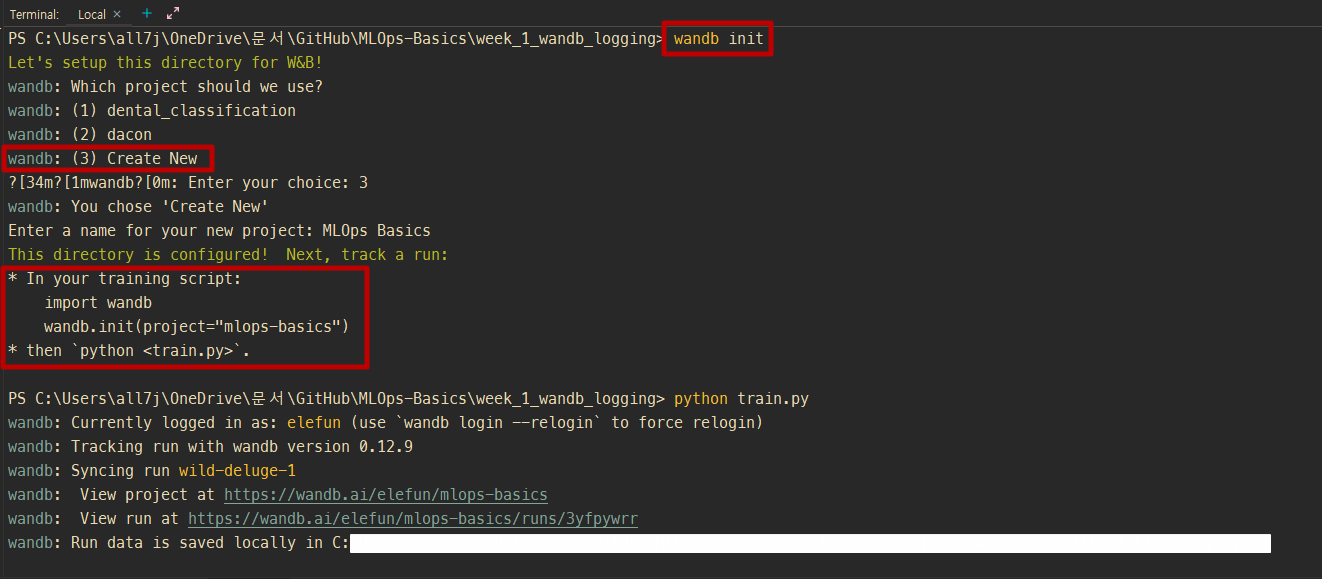
PyCharm을 이용하시는 분들은 이렇게 하시면 됩니다.
- 터미널에서
wandb init으로 한 번 초기화 시키기 (3) Create New옵션으로 레포 만들기- train.py에
wandb.init(project="mlops-basics")추가하기
📐Metrics
Metrics 계산은 때때로 어려울 수 있습니다. 다행히 pytorch lighting 팀은 모든 주요 Metrics을 포함하는 라이브러리 torchmetrics을 구축하고 있습니다. 자세한 내용은 설명서를 확인하십시오.
문제는 분류에 관한 것이므로 다음과 같은 Metrics을 계산하는 방법을 살펴보겠습니다.
Accuracy, Precision, Recall, F1
일단 import를 해야겠죠
import torchmetrics
__init__ 에 metrics을 선언해줍니다
class ColaModel(pl.LightningModule):
def __init__(self, model_name="google/bert_uncased_L-2_H-128_A-2", lr=3e-5):
self.train_accuracy_metric = torchmetrics.Accuracy()
self.val_accuracy_metric = torchmetrics.Accuracy()
self.f1_metric = torchmetrics.F1(num_classes=self.num_classes)
self.precision_macro_metric = torchmetrics.Precision(
average="macro", num_classes=self.num_classes
)
self.recall_macro_metric = torchmetrics.Recall(
average="macro", num_classes=self.num_classes
)
self.precision_micro_metric = torchmetrics.Precision(average="micro")
self.recall_micro_metric = torchmetrics.Recall(average="micro")
위와 같이 해두면 학습할 때, 검증할 때, 테스트할 때 계산할 수 있습니다.
Pytorch Lightning Module ⚡️에는 메트릭 계산을 구현할 위치를 쉽게 지정할 수 있는 다양한 방법이 있습니다.
일반적으로 계산되는 두 가지 주요 방법은 다음과 같습니다.
training_step: training data 배치가 처리되는 곳입니다.training loss,training_accuracy이런 메트릭이 여기서 계산 됩니다validation_step: validation data 배치가 처리되는 곳입니다.validation_loss,validation_accuracy이런 메트릭이 여기서 계산 됩니다.
다른 방법도 사용할 수 있습니다.
training_epoch_end: 모든 훈련 에포크가 끝날 때 호출됩니다.training_step이 반환하는 모든 데이터는 여기에서 집계할 수 있습니다.validation_epoch_end: 모든 훈련 에포크가 끝날 때 호출됩니다.training_step이 반환하는 모든 데이터는 여기에서 집계할 수 있습니다.test_step: 이것은 trainer가 테스트 메소드 즉,trainer.test()로 호출될 때 호출됩니다.test_epoch_end: 모든 테스트 배치가 끝날 때 호출됩니다.
로깅에 사용할 수 있는 몇 가지 구성
- Setting
prog_bar=True진행률 표시줄에 메트릭을 표시할 수 있습니다. - Setting
on_epoch=True, 메트릭은 한 에포크의 일괄 처리에서 집계되고 평균 처리됩니다 - Setting
on_step=True, 각 배치에 대해 기록됩니다. (useful for loss)
By default:
- Logging in
training_stephason_step=True - Logging in
validation_stephason_step=False,on_epoch=True
더 자세한 내용은 !여기!
다시 돌아와서 어떻게 메트릭이 계산되고 로그를 남기는지 확인해보겠습니다.
def training_step(self, batch, batch_idx):
outputs = self.forward(
batch["input_ids"], batch["attention_mask"], labels=batch["label"]
)
# loss = F.cross_entropy(logits, batch["label"])
preds = torch.argmax(outputs.logits, 1)
train_acc = self.train_accuracy_metric(preds, batch["label"])
self.log("train/loss", outputs.loss, prog_bar=True, on_epoch=True)
self.log("train/acc", train_acc, prog_bar=True, on_epoch=True)
return outputs.loss
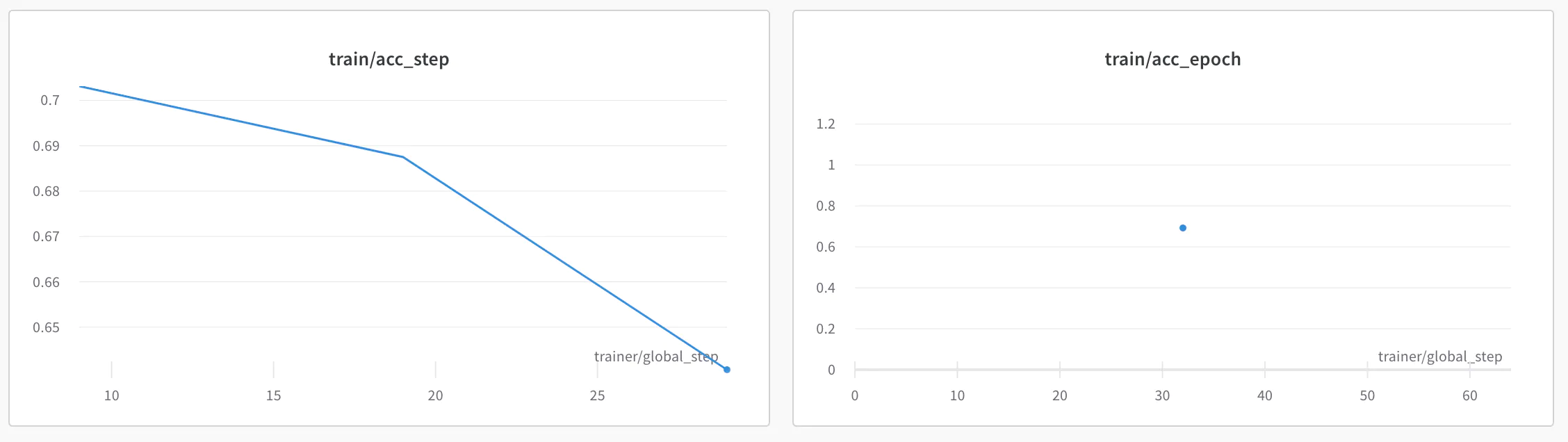
on_epoch=True가 활성화되어 있으므로 W&B 🏋️의 플롯에는 train/loss_step, train/loss_epoch 및 train/acc_step, train/acc_epoch가 있습니다.
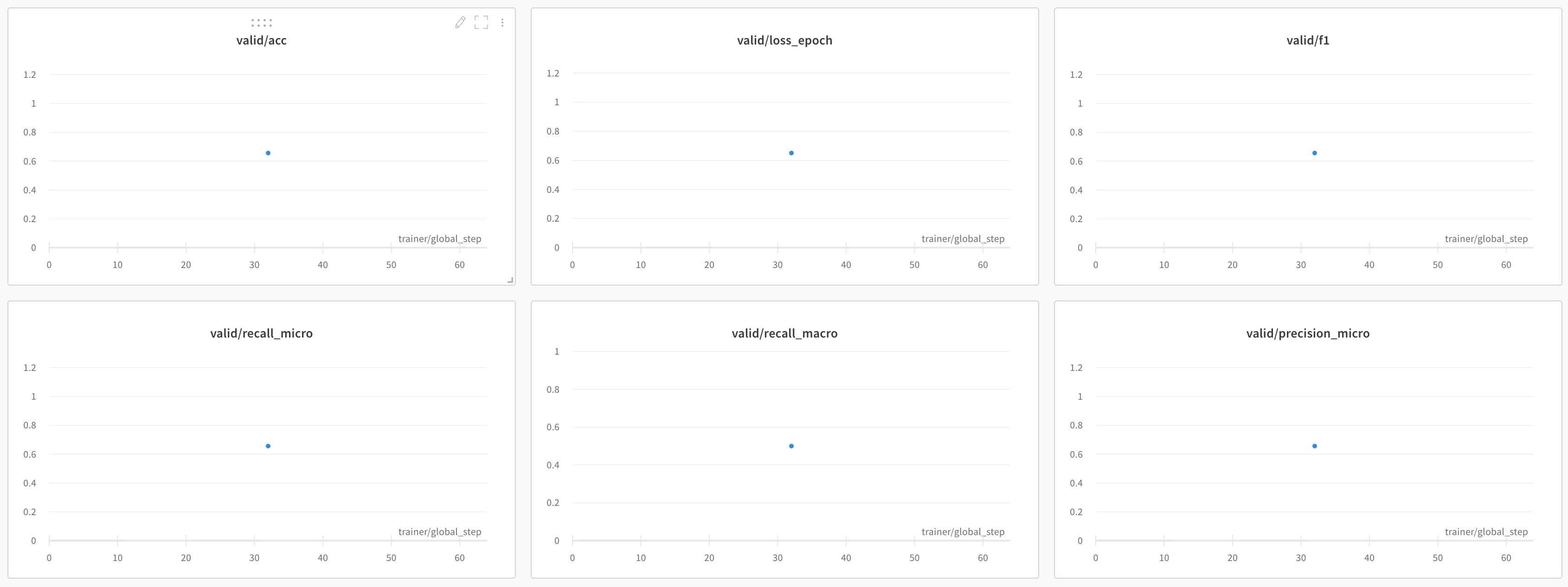
검증하는 동안 Precision, Recall, F1과 같은 더 많은 메트릭을 모니터링할 수 있습니다.
'''
__init__(self, model ..., lr=3e-5):
...
...
...
self.train_accuracy_metric = torchmetrics.Accuracy()
self.val_accuracy_metric = torchmetrics.Accuracy()
self.f1_metric = torchmetrics.F1(num_classes=self.num_classes)
self.precision_macro_metric = torchmetrics.Precision(
average="macro", num_classes=self.num_classes
)
self.recall_macro_metric = torchmetrics.Recall(
average="macro", num_classes=self.num_classes
)
self.precision_micro_metric = torchmetrics.Precision(average="micro")
self.recall_micro_metric = torchmetrics.Recall(average="micro")
'''
def validation_step(self, batch, batch_idx):
labels = batch["label"]
outputs = self.forward(
batch["input_ids"], batch["attention_mask"], labels=batch["label"]
)
preds = torch.argmax(outputs.logits, 1)
# Metrics
valid_acc = self.val_accuracy_metric(preds, labels)
precision_macro = self.precision_macro_metric(preds, labels)
recall_macro = self.recall_macro_metric(preds, labels)
precision_micro = self.precision_micro_metric(preds, labels)
recall_micro = self.recall_micro_metric(preds, labels)
f1 = self.f1_metric(preds, labels)
# Logging metrics
self.log("valid/loss", outputs.loss, prog_bar=True, on_step=True)
self.log("valid/acc", valid_acc, prog_bar=True)
self.log("valid/precision_macro", precision_macro, prog_bar=True)
self.log("valid/recall_macro", recall_macro, prog_bar=True)
self.log("valid/precision_micro", precision_micro, prog_bar=True)
self.log("valid/recall_micro", recall_micro, prog_bar=True)
self.log("valid/f1", f1, prog_bar=True)
return {"labels": labels, "logits": outputs.logits}
validation_step 동안 반환된 값은 validation_epoch_end에서 집계될 수 있으며 이를 사용하여 모든 변환을 수행할 수 있습니다.
예를 들어 위의 코드 조각 레이블에 표시된 것처럼 logit이 반환됩니다.
이 값은 validation_epoch_end 메서드에서 집계될 수 있으며 혼동 행렬과 같은 메트릭을 계산할 수 있습니다.
def validation_epoch_end(self, outputs):
labels = torch.cat([x["labels"] for x in outputs]) # 정답
logits = torch.cat([x["logits"] for x in outputs]) # 예측한 logit
preds = torch.argmax(logits, 1) # argmax를 통해 제일 높은 확률을 가진 값을 반환
cm = confusion_matrix(labels.numpy(), preds.numpy())
📈Adding Plots to
Logging Metrics은 충분하지 않을 수 있습니다. 그래프 및 플롯과 같은 시각적 정보가 많을수록 모델 성능을 더 잘 이해하는 데 도움이 됩니다. 그래프를 그리는 방법은 여러 가지가 있습니다. 몇 가지 방법을 살펴보겠습니다.
Document 예를 들어 위에서 계산한 Confusion_matrix를 그리는 방법을 살펴보겠습니다.
Metchod 1
# 1. Confusion matrix plotting using inbuilt W&B method
self.logger.experiment.log(
{
# wandb.plot.scatter&bar&line_series&line&histogram&roc_curve 등등
"conf": wandb.plot.confusion_matrix(
probs=logits.numpy(), y_true=labels.numpy()
)
}
)
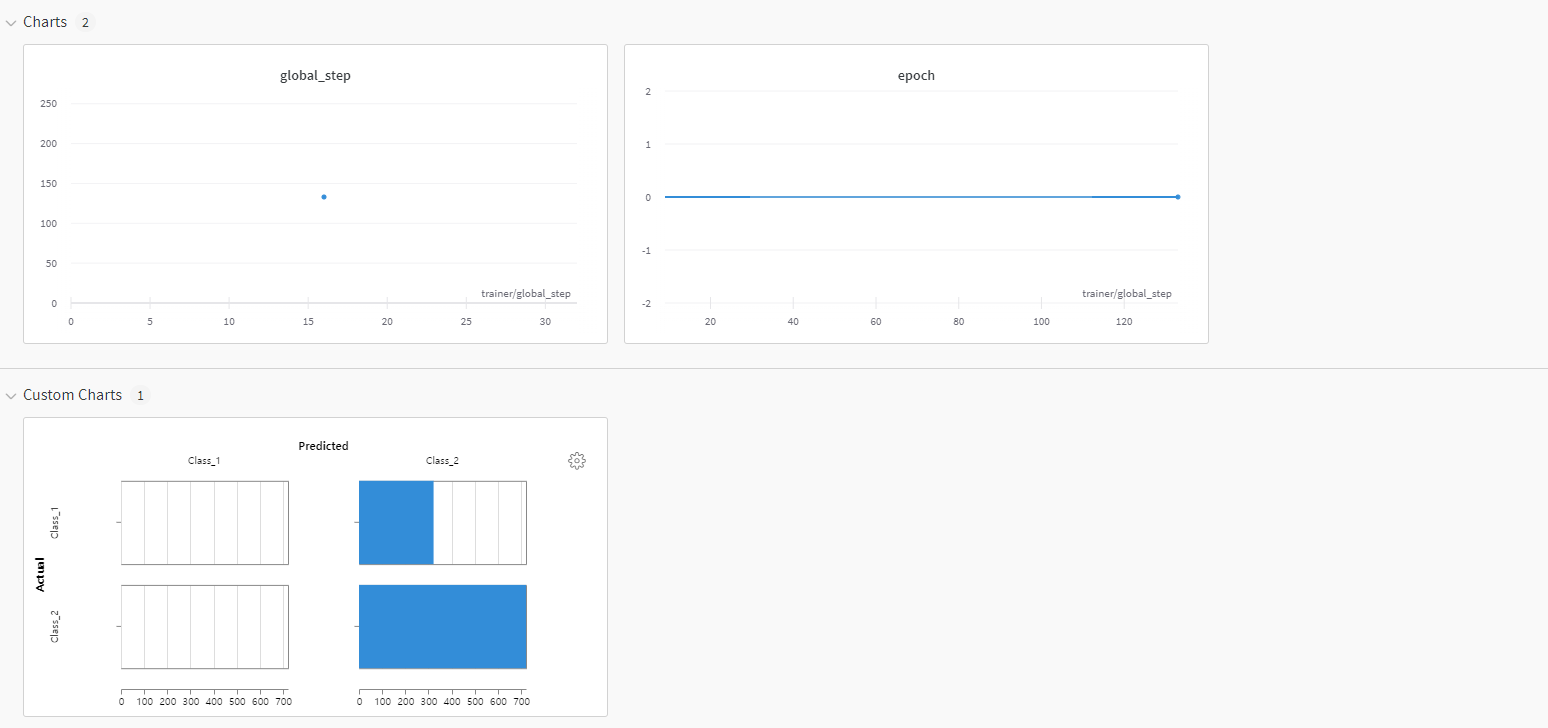
Metchod 2
또한, 문서를 읽던 중에 기존에 저희가 사용하던 matplotlib나 plotly와도 같이 사용할 수 있는 것을 확인했습니다.
import matplotlib.pyplot as plt
plt.plot([1, 2, 3, 4])
plt.ylabel("some interesting numbers")
wandb.log({"chart": plt})
단순하게 matplotlib의 figure object를 wandb.log에 넣어 주시면 됩니다.
만약 “You attempted to log an empty plot” 같은 에러를 만나셨다면 fig= plt.figure() 에 넣어 주신 다음에 진행하시면 됩니다.
또는
# 3. Confusion Matric plotting using Seaborn
data = confusion_matrix(labels.numpy(), preds.numpy())
df_cm = pd.DataFrame(data, columns=np.unique(labels), index=np.unique(labels))
df_cm.index.name = "Actual"
df_cm.columns.name = "Predicted"
plt.figure(figsize=(10, 5))
plot = sns.heatmap(
df_cm, cmap="Blues", annot=True, annot_kws={"size": 16}
) # font size
self.logger.experiment.log({"Confusion Matrix": wandb.Image(plot)})
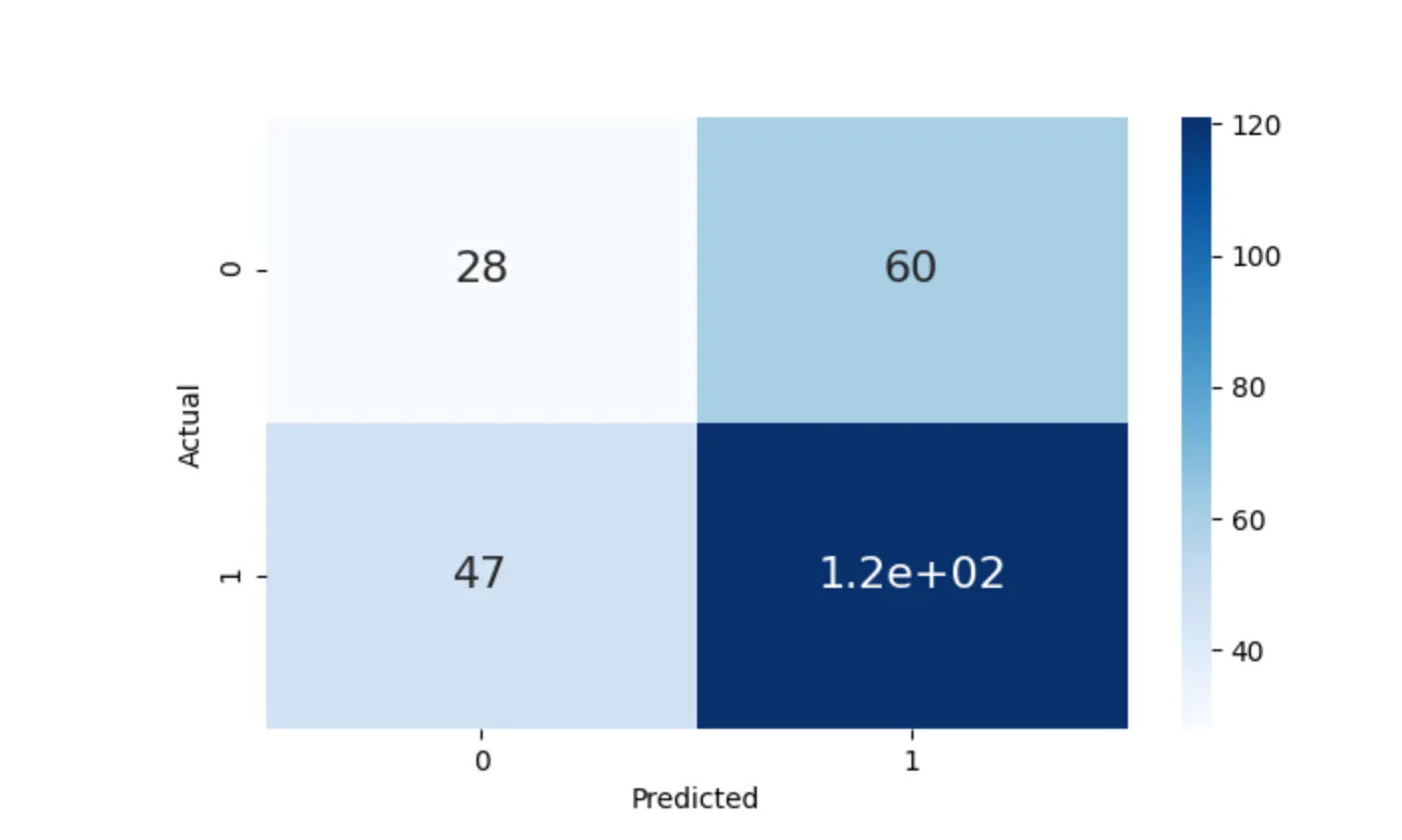
Metchod 3
matplotlib 뿐만 아니라 scikit-learn도 지원해준다고 합니다.
# 2. Confusion Matrix plotting using scikit-learn method
wandb.log({"cm": wandb.sklearn.plot_confusion_matrix(labels.numpy(), preds)})

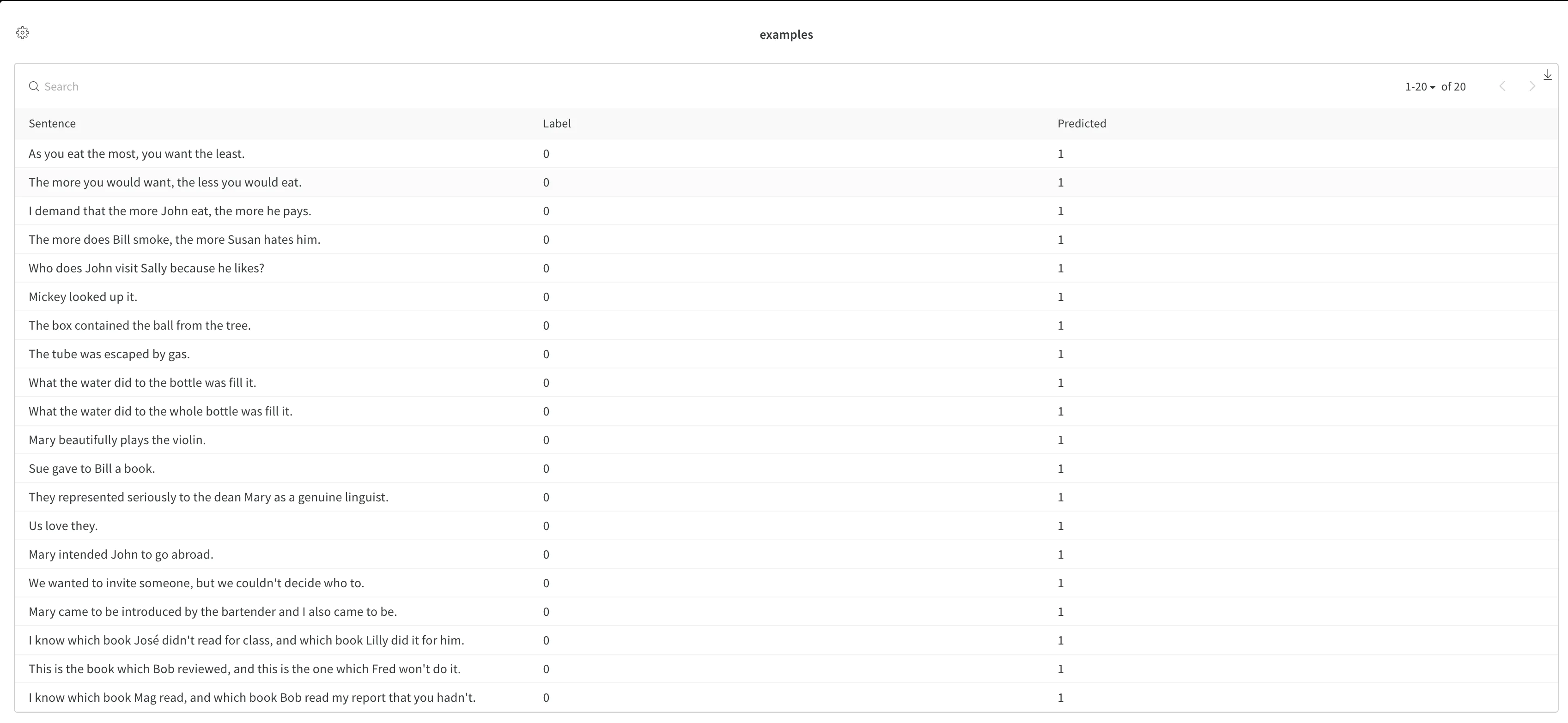
📑Adding Data samples to
모델이 학습되면 모델이 잘 수행되는 부분과 그렇지 않은 부분을 이해해야 합니다.
우리는 cola 문제에 대해 작업 중이므로 모델이 잘 수행되지 않는 몇 가지 샘플을 보고 W&B에 기록해 보겠습니다.
데이터를 플로팅하는 방법에는 여러 가지가 있을 수 있습니다.
자세한 내용은 여기에서 문서를 참조하십시오.
이것은 ⚡️에서 콜백 🔁 메커니즘을 통해 달성할 수 있습니다.
class SamplesVisualisationLogger(pl.Callback):
def __init__(self, datamodule):
super().__init__()
self.datamodule = datamodule
def on_validation_end(self, trainer, pl_module):
# can be done on complete dataset also
val_batch = next(iter(self.datamodule.val_dataloader()))
sentences = val_batch["sentence"]
# get the predictions
outputs = pl_module(val_batch["input_ids"], val_batch["attention_mask"])
preds = torch.argmax(outputs.logits, 1)
labels = val_batch["label"]
# predicted and labelled data
df = pd.DataFrame(
{"Sentence": sentences, "Label": labels.numpy(), "Predicted": preds.numpy()}
)
# wrongly predicted data
wrong_df = df[df["Label"] != df["Predicted"]]
# Logging wrongly predicted dataframe as a table
trainer.logger.experiment.log(
{
"examples": wandb.Table(dataframe=wrong_df, allow_mixed_types=True),
"global_step": trainer.global_step,
}
)
그리고 나서 콜백🔁을 넣어 줍니다!
trainer = pl.Trainer(
max_epochs=3,
logger=wandb_logger,
callbacks=[checkpoint_callback, SamplesVisualisationLogger(cola_data)],
log_every_n_steps=10,
deterministic=True,
)